Instance-level Image Retrieval using Reranking Transformers
Sintesi del comunicato stampa
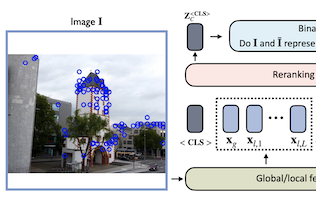
Ricercatori di University of Virginia, eBay e Rice University hanno sviluppato un modello di rete neurale leggero chiamato Reranking Transformer, o RRT, che migliora l'accuratezza dei sistemi di ricerca di immagini che cercano di identificare oggetti o monumenti specifici anziché categorie generiche. Il problema affrontato dal team è un processo in due fasi comune nel recupero di immagini: una prima fase usa un descrittore globale compatto dell'immagine per estrarre una rosa ristretta di possibili corrispondenze, e una seconda fase raffina quell'elenco utilizzando caratteristiche locali più dettagliate — una fase tradizionalmente affidata alla verifica geometrica, una tecnica computazionalmente onerosa che cerca di stimare come un'immagine possa essere deformata geometricamente per corrispondere a un'altra. I ricercatori hanno sostituito quella seconda fase con un piccolo modello basato su transformer, prendendo in prestito l'architettura basata sull'attenzione che ha guidato i recenti progressi nell'elaborazione del linguaggio naturale, e lo hanno addestrato a prevedere direttamente se due immagini mostrano lo stesso oggetto o la stessa scena. Con appena 2,2 milioni di parametri circa — all'incirca il 9 percento delle dimensioni di una backbone ResNet50 standard — e richiedendo solo la metà dei descrittori di caratteristiche locali rispetto alla verifica geometrica, RRT ha comunque superato la verifica geometrica e altri approcci concorrenti sui benchmark standard, tra cui i dataset Revisited Oxford e Paris e Google Landmarks v2. Un vantaggio pratico fondamentale è che riordinare un'intera rosa di 100 immagini candidate richiede una sola passata in avanti attraverso la rete. I ricercatori hanno inoltre mostrato che, a differenza della verifica geometrica, RRT può essere addestrato congiuntamente all'estrattore di caratteristiche sottostante, permettendo di ottimizzare insieme i due componenti e ottenendo ulteriori guadagni di accuratezza, una capacità che hanno dimostrato sul dataset Stanford Online Products.
abstract
Il recupero di immagini a livello di istanza è il compito di cercare in un grande database immagini che corrispondano a un oggetto presente in un'immagine di query. Per affrontare questo compito, i sistemi si basano di solito su una fase di recupero che usa descrittori globali dell'immagine e su una fase successiva che esegue raffinamenti specifici per dominio o un riordinamento (reranking) sfruttando operazioni come la verifica geometrica basata su caratteristiche locali. In questo lavoro proponiamo i Reranking Transformers (RRT) come modello generale per incorporare sia caratteristiche locali sia globali al fine di riordinare le immagini corrispondenti in modo supervisionato, sostituendo così il processo relativamente costoso della verifica geometrica. Gli RRT sono leggeri e facilmente parallelizzabili, così che il riordinamento di un insieme dei migliori risultati corrispondenti possa essere eseguito in un'unica passata in avanti (forward-pass). Conduciamo esperimenti estesi sui dataset Revisited Oxford e Paris e sul dataset Google Landmarks v2, mostrando che gli RRT superano i precedenti approcci di riordinamento utilizzando molti meno descrittori locali. Inoltre, dimostriamo che, a differenza degli approcci esistenti, gli RRT possono essere ottimizzati congiuntamente all'estrattore di caratteristiche, il che può portare a rappresentazioni delle caratteristiche adattate ai compiti downstream e a ulteriori miglioramenti dell'accuratezza. Il codice e i modelli addestrati sono pubblicamente disponibili all'indirizzo https://github.com/uvavision/RerankingTransformer.
dettagli
citazione
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}