Obj2Text: Generating Visually Descriptive Language from Object Layouts
Sintesi del comunicato stampa
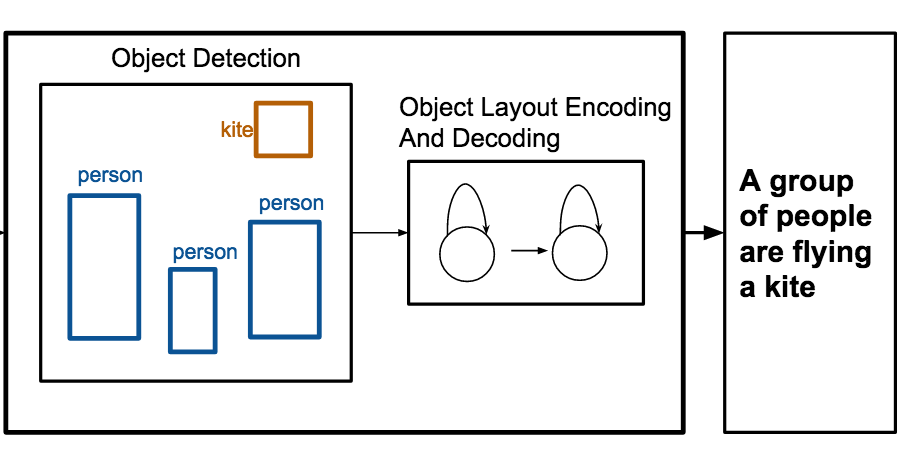
I ricercatori della University of Virginia hanno realizzato un sistema in grado di scrivere automaticamente didascalie che descrivono una scena utilizzando nient'altro che un elenco di oggetti e le loro posizioni in un'immagine, aggirando la necessità di dati grezzi a livello di pixel. Il sistema, chiamato OBJ2TEXT, funziona inserendo le etichette degli oggetti e le coordinate dei loro riquadri di delimitazione in una rete neurale che codifica il layout come sequenza, per poi passare tale rappresentazione codificata a una seconda rete neurale che genera una frase parola per parola. Testando sul dataset di immagini standard MS-COCO, il gruppo ha riscontrato che sia la posizione degli oggetti sia il loro numero miglioravano in modo significativo la qualità delle didascalie — rimuovendo l'uno o l'altro si registravano cali misurabili nelle prestazioni — dimostrando che persino una codifica sequenziale delle informazioni spaziali ha un reale valore descrittivo. Forse ancora più rilevante sul piano pratico, quando i ricercatori hanno combinato OBJ2TEXT con un rilevatore di oggetti chiamato YOLO e un modello convenzionale di generazione di didascalie basato su immagini, il sistema ibrido ha superato il modello di riferimento basato solo sulle immagini, portando il suo punteggio CIDEr da 0,863 a 0,950 sul benchmark MS-COCO; inoltre i valutatori umani hanno preferito le didascalie del sistema combinato circa il 65 percento delle volte in cui erano tutti concordi. Il lavoro è importante perché mostra che le informazioni strutturate e simboliche su una scena — quelle prodotte dai rilevatori di oggetti o utilizzate nella grafica e negli storyboard — possono integrare o persino sostituire parzialmente le caratteristiche visive a livello di pixel nella generazione del linguaggio, offrendo un modo più pulito per studiare ciò che i modelli di generazione di didascalie devono effettivamente sapere di una scena.
abstract
Generare didascalie per le immagini è un compito che ha recentemente ricevuto notevole attenzione. In questo lavoro ci concentriamo sulla generazione di didascalie per scene astratte, ovvero layout di oggetti in cui le uniche informazioni fornite sono un insieme di oggetti e le loro posizioni. Proponiamo OBJ2TEXT, un modello sequence-to-sequence che codifica un insieme di oggetti e le loro posizioni come sequenza di input utilizzando una rete LSTM, e decodifica questa rappresentazione mediante un modello linguistico LSTM. Mostriamo che il nostro modello, pur codificando i layout di oggetti come sequenza, è in grado di rappresentare le relazioni spaziali tra gli oggetti e di generare descrizioni globalmente coerenti e semanticamente rilevanti. Mettiamo alla prova il nostro approccio in un compito di generazione di didascalie da layout di oggetti utilizzando come input unicamente le annotazioni degli oggetti. Mostriamo inoltre che il nostro modello, combinato con un rilevatore di oggetti allo stato dell'arte, migliora un modello di generazione di didascalie per immagini da 0,863 a 0,950 (punteggio CIDEr) nel benchmark di test del compito standard MS-COCO Captioning.
dettagli
citazione
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}