Going Beyond Nouns With Vision & Language Models Using Synthetic Data
プレスリリース要約
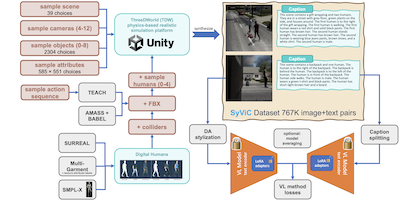
MIT、IBM、ライス大学、その他いくつかの機関の研究者らは、CLIPのような人気のAI視覚言語モデルにおける根強い盲点を特定し、それを修正するための実用的な一歩を踏み出しました。これらのシステムは、画像内の物体以外のものを理解するのが驚くほど不得意であり、人間にとっては自明な仕方で属性、空間的関係、動作、語順を把握することに苦戦します。これに対処するため、研究チームは、ThreeDWorldエンジンで物理ベースの3Dシミュレーションを実行し、ランダム化された物体、材質、多様な服装をまとったアニメーション付きの人間アバターでシーンを構成し、シーンのメタデータから詳細なテキストキャプションを自動生成することで、SyViC(Synthetic Visual Concepts)と呼ばれる百万枚規模の合成画像データセットを構築しました。重要な洞察は、合成環境によって研究者が、モデルが取りこぼすまさにその非名詞的概念を意図的に強調する画像テキストペアを安価に作成できることであり、これは実世界の写真で行うには極めて困難でコストがかかることです。低ランクパラメータ適応(LoRA)、スタイル転送ベースのドメイン適応、より長い記述的テキストを扱うためのキャプション分割技術を組み合わせてCLIPとCyCLIPをSyViCでファインチューニングしたところ、モデルはAROの構成的推論ベンチマークで最大9.9%、VL-Checklistの評価で4.3%向上した一方、21のタスクにわたるゼロショット分類精度の犠牲は1パーセント未満にとどまりました。この研究が重要なのは、実画像を一切用いない的を絞った合成データが、対照的な視覚言語訓練における十分に文書化された構造的弱点を有意に修復できることを実証しているからであり、研究チームはデータセットとコードの両方を公開しています。
要旨
大規模な事前学習済み視覚言語(VL)モデルは多くのアプリケーションで目覚ましい性能を示しており、固定された対応クラスの集合を、(ほぼ任意の)自然言語プロンプトに対するゼロショットのオープン語彙推論に置き換えることを可能にしています。しかし、最近の研究は、これらのモデルの根本的な弱点を明らかにしました。たとえば、非物体の語(属性、動作、関係、状態など)の意味のように「名詞を超える」視覚言語概念(VLC)を理解することの難しさ、あるいは文中の語順の重要性を理解するといった構成的推論を行うことの難しさです。本研究では、これらのモデルがそのような欠点を克服することを、ゼロショット能力を損なうことなく教えるために、純粋に合成されたデータをどの程度活用できるかを調査します。私たちは、Synthetic Visual Concepts(SyViC)を提供します。これは、VLモデルのVLC理解と構成的推論を改善するための適切な追加データを生成できる、百万規模の合成データセットおよびデータ生成コードベースです。さらに、これらの改善を達成するためにSyViCを効果的に活用する汎用的なVLファインチューニング戦略を提案します。VL-Checklist、Winoground、AROベンチマークにおける私たちの広範な実験とアブレーションは、合成データを用いて強力な事前学習済みVLモデルを適応させ、ゼロショット精度の低下を1%未満に抑えながら、そのVLC理解を大幅に向上させること(たとえばAROで9.9%、VL-Checklistで4.3%)が可能であることを実証しています。
詳細
引用
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}