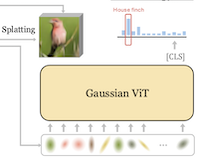
プレスリリース要約
ライス大学とカリフォルニア大学アーバイン校の研究者らは、ニューラルネットワークにピクセルや矩形パッチのグリッドを与える従来のアプローチを捨て、その入力を2Dガウシアンと呼ばれる数学的な塊のコンパクトな集合で置き換える、新しい画像分類システムを構築した。GViTと呼ばれるこのシステムは、各画像を数百個のガウシアンを用いて記述するよう小さなエンコーダネットワークを訓練することで機能し、各塊はその位置、サイズ、向き、色、不透明度に関する情報を担う。この訓練設定の巧妙な点は、分類モデルとガウシアンエンコーダがフィードバックループの中で一緒に訓練されることである。分類器からの勾配、本質的には画像のどの部分が内容を識別する上で重要かに関する信号がフィードバックされ、ガウシアンを情報量のない背景に一様に広げさせるのではなく、認識に実際に有用な領域へと向かわせる。標準的なImageNet-1kベンチマークでこのアプローチを用いて、GViTの最良版はViT-Baseアーキテクチャで76.9%のトップ1精度に達した。これは同程度の規模の従来のパッチベースのViTの約78.7%と比較したもので、根本的に異なるはるかにコンパクトな入力表現を用いながら、その差は2パーセントポイント未満である。本研究が重要なのは、それが既存のシステムを即座に上回るからではなく、中間的で人間が解釈可能な幾何学的プリミティブが競争力のある視覚認識を支え得ることを実証しているからである。そして副産物として、学習されたガウシアンはモデルが最も識別的だと判断するシーンの部分の周りに集まる傾向があり、ピクセルグリッドモデルが自然には提供しない軽量な形の説明可能性をもたらす。
要旨
我々は、従来のピクセルやパッチのグリッド入力表現を放棄し、学習可能な2Dガウシアンのコンパクトな集合を採用する分類フレームワークであるGVITを導入する。各画像は数百個のガウシアンとして符号化され、その位置、スケール、向き、色、不透明度は、これらの表現の上で訓練されるViT分類器とともに同時に最適化される。我々は分類器の勾配を建設的な誘導として再利用し、微分可能なレンダラーが画像再構成損失を最適化する一方で、ガウシアンをクラスに顕著な領域へと向かわせる。比較的標準的なViTアーキテクチャを用いて、2Dガウシアン入力表現を我々のGVIT誘導と組み合わせることで、従来のパッチベースのViTの性能に肉薄し、ViT-Bアーキテクチャを用いてImagenet-1kで76.9%のトップ1精度に達することを実証する。
引用
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- GViTとは何であり、どのような問題に取り組むのか。GViTは、固定されたピクセルやパッチグリッドの入力を学習可能な2Dガウシアンプリミティブのコンパクトな集合で置き換える視覚認識フレームワークであり、中間レベルの幾何学的表現が競争力のある画像分類を支え得るかどうかを検証する。
- ガウシアンはどのように学習されるのか。ノイズ除去ガウシアンエンコーダがガウシアンの中心、スケール、向き、色、不透明度を予測する一方で、微分可能なレンダラーが画像再構成を最適化し、ViT分類器がガウシアンをクラスに顕著な領域へと向かわせる建設的な勾配を供給する。
- GViTはImageNet-1kでどの程度の性能を示すか。誘導されたGViT-BモデルはImageNet-1kで76.9パーセントのトップ1精度に達し、これは大きく異なるガウシアン入力表現を用いながら、同程度の規模のパッチベースのViT-B/16について報告された78.7パーセントに近い。
- なぜ分類器勾配による誘導が重要なのか。本論文は、誘導がImageNet-1kにおいてGViT-Bを73.6パーセントから76.9パーセントへと向上させ、より小さなモデルも同様に向上させることを報告しており、タスクを意識したガウシアンの配置がこの表現を認識に有用なものにする上で中心的であることを示している。
- GViTは解釈可能性の利点を提供するか。然り、学習されたガウシアンの共分散とクラス識別的なアテンションマップは、クラスに関連する画像領域に集中する傾向があり、標準的なパッチトークンが自然には露呈しない幾何学的な視覚的説明をこの表現に与える。
主な貢献
- 本論文は、ピクセル、パッチ、生バイト、あるいは圧縮された周波数係数ではなく、2Dガウシアンプリミティブの集合に基づくViT互換の画像表現を導入する。
- GViTは、再構成損失が画像の忠実度を保持する一方で、分類器の勾配がガウシアンを識別的な視覚的証拠へと能動的に再配置する協調的な訓練スキームを提案する。
- ImageNet-1kの実験は、ガウシアン入力がViT-Bバックボーンで76.9パーセントのトップ1精度に達し得ることを示しており、これは本論文に列挙されたいくつかの非パッチ入力の代替手法を上回り、従来のパッチベースのViT-B/16との差が1.8ポイント以内に収まる。
- Mini-ImageNet-100でのアブレーションは、ノイズ除去と分類器勾配による誘導がガウシアンの配置を意味のある形で改善することを示しており、完全に誘導された版はオフラインのガウシアン当てはめ、学習されたクエリ、誘導なしのノイズ除去を上回る。
- 分析は、ガウシアンのスケールとアテンション信号がクラス識別的な領域と一致することを示しており、GViTが自然な解釈可能性の要素を備えたコンパクトな認識表現を提供するという主張を裏付けている。
限界と注意点
- パッチベースのViTは今日でも多くの大規模展開にとって最も実用的な選択肢であり続けているが、GViTのImageNet-1kにおける小さな精度差は、ガウシアンプリミティブがすでに実行可能で驚くほど競争力のある代替表現であることを強く裏付けている。
- ガウシアンの数は訓練前に固定されるため、将来の版は動的な生成、剪定、再割り当てから恩恵を受けられるだろう。ガウシアンの予算が増加するにつれて観察される単調な向上は、その次の設計のステップに有用な指針を提供する。
- 微分可能なレンダリングは、特に高解像度やImageNet規模の訓練で512個を超えるガウシアンを用いる場合に、メモリと計算のオーバーヘッドを加える。これは、中心的な発想の弱点というよりは、それ以外は有望な表現にまつわる工学的なボトルネックである。
- 実験は、検出やセグメンテーションのような密な予測タスクではなく、画像分類および転移分類のベンチマークに焦点を当てている。クラスに顕著なガウシアンの配置は、それらのタスクがこの表現を次に探究する自然な場であることを示唆している。
- 現在のアプローチは設計上、いくらかのきめ細かいピクセルの詳細を圧縮によって失っており、これは表現をコンパクトで解釈可能にするのに役立つ一方で、再構成の忠実度と意味的な識別性のバランスを調整する今後の研究の余地を残している。
この結果の読み解き方
本論文は、視覚認識がピクセルやパッチのグリッドに縛られる必要はないという、証拠に裏打ちされた強力な主張として読むのが最も適切である。すなわち、GViTはImageNetの性能を標準的なViTに近く保ちながら、将来の視覚バックボーンに有望な方向を開く解釈可能なガウシアン表現を導入している。