プレスリリース要約
MetaおよびRice大学の研究者らは、システムが必要に応じて精度と速度を調整できるようにする、マルチモーダル検索への新しいアプローチであるMetaEmbedを開発しました。テキストと画像にわたって検索する現在のマルチモーダル検索システムは、精度と計算効率の間のトレードオフに直面しています。すなわち、すべてを詳細が失われる単一のベクトルに圧縮するか、実用には遅すぎる数百のベクトルを使用するかのいずれかです。MetaEmbedは、粗い情報から細粒度の情報まで整理された小規模な文脈化埋め込みのセットを生成する、学習可能な「Meta Token」を導入します。この設計により、ユーザーは検索時に使用するベクトル数を選択し、品質と速度の要件のバランスを取ることができます。標準ベンチマークでのテストは、本システムがスケールしながら最先端の性能を達成することを示しています。
要旨
汎用的なマルチモーダル埋め込みモデルは、クエリと候補の間の意味的関連性を捉える点で大きな成功を収めてきました。しかし、現在の手法は、クエリと候補を単一のベクトルに凝縮するため細粒度の情報に対する表現力が制限される可能性があるか、あるいは多すぎるベクトルを生成するためマルチベクトル検索には非現実的であるかのいずれかです。本研究では、マルチモーダル埋め込みを大規模にどのように構築し、どのように相互作用させるかを再考した、マルチモーダル検索のための新しいフレームワークであるMetaEmbedを提案します。学習時には、一定数の学習可能なMeta Tokenが入力シーケンスに付加されます。テスト時には、その最終層の文脈化表現が、コンパクトながら表現力豊かなマルチベクトル埋め込みとして機能します。提案するMatryoshka Multi-Vector Retrieval学習を通じて、MetaEmbedは複数のベクトルにわたって情報を粒度ごとに整理することを学習します。その結果、ユーザーがインデックス作成および検索の相互作用に使用するトークン数を選択することで、検索品質と効率性の要求のバランスを取れる、マルチモーダル検索におけるテスト時スケーリングを可能にします。Massive Multimodal Embedding Benchmark(MMEB)およびVisual Document Retrieval Benchmark(ViDoRe)における広範な評価により、MetaEmbedが最先端の検索性能を達成し、32Bパラメータのモデルまで堅牢にスケールすることが確認されました。コードはhttps://github.com/facebookresearch/MetaEmbed で入手できます。
詳細
引用
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
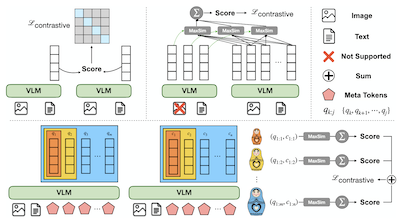
- MetaEmbedとは何で、どのような問題に取り組んでいるのか。MetaEmbedは、数百のパッチレベルのベクトルという重いコストを伴うことなく、単一ベクトル埋め込みよりも表現力豊かな検索を提供するために、コンパクトで学習可能なMeta Tokenを使用するマルチモーダル検索フレームワークです。
- MetaEmbedはどのようにしてテスト時スケーリングを可能にするのか。Matryoshka Multi-Vector Retrievalを通じて入れ子状のMeta Embeddingグループを学習するため、ユーザーは再学習することなく、インデックス作成時およびスコアリング時により小さい、またはより大きい検索予算を選択できます。
- なぜMeta Tokenはマルチモーダル検索に有用なのか。その最終層の文脈化された状態は、細粒度のクエリと候補の相互作用を保持しつつ、インデックスサイズとスコアリングコストを制御可能に保つ、小規模なマルチベクトル埋め込みのセットとして機能します。
- MetaEmbedはMMEBでどの程度の性能を発揮するのか。論文では、Qwen2.5-VLで初期化したMetaEmbedが、7Bモデルで全体のPrecision@1が76.6、32Bモデルで78.7に達し、列挙したベースラインを上回ったと報告しています。
- MetaEmbedは視覚的文書検索でも機能するのか。はい、論文ではViDoReで評価し、より多くのMeta Embeddingを使用するにつれて検索品質が向上する一方、MMRが低い検索予算でも強力な性能を維持することを示しています。
主な貢献
- 本論文は、テキスト、画像、混合モダリティのクエリと候補にわたるマルチモーダル検索のための、コンパクトで文脈化されたマルチベクトル埋め込みとしてのMeta Tokenを導入します。
- Matryoshka Multi-Vector Retrievalは、粗いものから細かいものへと入れ子状になった埋め込みグループを学習し、単一のモデルとインデックス設計で複数の品質とレイテンシの動作点をサポートできるようにします。
- MetaEmbedは、32Bの視覚言語モデルのバックボーンまでスケールしながら、MMEBで最先端の結果を、ViDoReで強力な結果を達成します。
- アブレーション研究は、マルチベクトル検索の利点がモデル規模とともに増大すること、また低予算での検索品質を保持するためにMMRが重要であることを示しています。
- 効率性の分析は、適度な予算ではスコアリングのレイテンシが小さく保たれること、またバランスの取れた検索設定を選択することでインデックスメモリを管理できることを示しています。
限界と注意点
- より高い検索予算はインデックスメモリを増加させますが、入れ子状の設計により、これは固定的な展開コストではなく、ユーザーが制御可能なトレードオフとなります。
- 最大の予算ではスコアリングのFLOPsが大幅に増加する可能性がありますが、測定されたレイテンシは多くの設定で実用的なままであり、論文ははるかに小さい予算でも有用な精度を示しています。
- MetaEmbedは依然として強力なVLMバックボーンのファインチューニングを必要とするため、今後の研究ではより軽量な学習レシピを探求できるでしょう。LoRAの設定とマルチアーキテクチャの実験は、すでに本アプローチを広く利用可能にしています。
- 評価は標準的なマルチモーダルおよび視覚的文書検索のベンチマークに焦点を当てており、非常に大規模な本番インデックスや専門的な企業ドメインは、自然な展開研究の対象として残されています。
- 本手法は、生成や質問応答を直接の対象とするのではなく検索を対象としていますが、より優れた柔軟な検索は、検索拡張型マルチモーダルシステムにとって価値ある構成要素です。
この結果の読み解き方
本論文は、スケーラブルなマルチモーダル検索への強力な貢献として読むのが最も適切です。MetaEmbedは細粒度の後期相互作用を保持し、実用的なテスト時の予算調整つまみを追加し、コンパクトなマルチベクトルインターフェースを与えられれば、より大規模なVLMがより効果的な検索モデルになり得ることを示しています。