プレスリリース要約
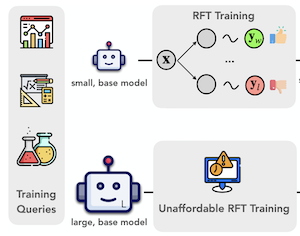
ライス大学、イリノイ大学アーバナ・シャンペーン校、バージニア大学の研究者らは、いかなる追加の訓練もなしに、大規模視覚言語モデルがテスト時により注意深く推論できるようにするProxyThinkerと呼ばれる手法を開発した。彼らが解決しようとした問題は実用的なものである。大規模なAIモデルに「ゆっくり進め」て複雑な視覚問題を一歩ずつ解かせるよう教えることは、一般に高価な強化ファインチューニングを必要とし、これは膨大な計算資源を要するプロセスで、70億パラメータより大きいモデルに適用されることはまれであった。ProxyThinkerは、推論中に大規模モデルと並んで二つの小さな伴走モデル、すなわち注意深く推論するようすでにファインチューニングされたものとそうでないものを実行し、それらの出力分布の差を用いて大規模モデルのトークンごとの生成を、より熟考的で自己点検的な推論へと誘導することで、そのコストを完全に回避する。実際には、これは大規模モデルが、さもなければめったに生み出さないであろう、後戻り、自己検証、複数ステップの訂正といった振る舞いを示し始めることを意味する。標準的な視覚的数学および複数分野にまたがるベンチマークでこのアプローチを検証したところ、研究チームは、弱い70億パラメータの推論エキスパートによって誘導された320億パラメータのベースモデルが、強化学習で完全にファインチューニングされた専用の320億パラメータのモデルの性能に匹敵するか、それをわずかに上回り得ることを見出した。研究チームはまた、vLLM推論フレームワークの上に、従来のデコーディング時の誘導手法より約38倍速く動作する並列化された実装を構築し、実時間の推論時間を単一の大規模モデルを実行するのに近づけた。本研究が重要なのは、最先端規模の強化ファインチューニングの訓練コストが大半の研究グループにとって手の届かないままである時代に、大規模モデルにおけるより強力な視覚推論への計算的に手の届く道を提供しているからである。
要旨
検証可能な報酬を用いた強化学習における近年の進歩は、大規模視覚言語モデル(LVLM)における視覚推論能力の限界を押し広げてきた。しかし、強化ファインチューニング(RFT)によるLVLMの訓練は計算上高価であり、モデルサイズのスケーリングに重大な課題を突きつけている。本研究では、大規模モデルが、いかなる訓練もなしに、小さくゆっくり考える視覚推論器から視覚推論能力を継承できるようにする推論時の技術であるProxyThinkerを提案する。RFT推論器の出力分布からベースモデルの出力分布を差し引くことで、ProxyThinkerはデコーディングの動態を修正し、自己検証や自己訂正といった出現した洗練された振る舞いによって実証される、ゆっくり考える推論をうまく引き出す。ProxyThinkerは、空間的、数学的、複数分野にまたがる推論に関する困難な視覚ベンチマークにおいて一貫して性能を高め、調整されていないベースモデルがその完全規模のRFT対応物の性能と競合できるようにする。さらに、我々の実装は並列化技術を用いて複数の言語モデルを効率的に協調させ、従来のデコーディング時の手法と比較して最大38$\times$高速な推論を達成し、ProxyThinkerの実用的な展開への道を切り開く。コードはhttps://github.com/MrZilinXiao/ProxyThinkerで入手可能である。
引用
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- ProxyThinkerとは何であり、どのような問題に取り組むのか。ProxyThinkerは訓練不要の推論時の手法であり、小さな強化ファインチューニング済みの視覚推論器から、より大きなベースの視覚言語モデルへと、ゆっくり考える視覚推論の振る舞いを転移させる。
- ProxyThinkerは大規模モデルをどのように誘導するのか。各デコーディングステップで、小さなRFT推論エキスパートとその小さなベースのアマチュア対応物との間のロジットの差を大規模なベースモデルのロジットに加え、大規模モデルが自己点検や複数ステップの推論に関連するトークンを生成するよう促す。
- この手法は完全な強化ファインチューニングと比較してなぜ有用なのか。大規模モデルのパラメータを更新することを回避するため、32Bや72Bの視覚言語モデルの完全規模の強化ファインチューニングがあまりに高価な場合の実用的な代替手段となる。
- ProxyThinkerは視覚推論のベンチマークをどの程度改善するのか。五つの数学的および複数分野にまたがるベンチマークにおいて、ProxyThinkerは小さな推論エキスパートに応じて、Qwen2.5-VL-32Bを平均相対改善で最大2.4パーセント、Qwen2.5-VL-72Bを平均相対改善で最大2.7パーセント改善する。
- ProxyThinkerは大規模モデルの推論スタイルを変えるか。然り、本論文はより多くの後戻り、検証、明示的な思考の振る舞いを報告しており、この手法が単に最終的な回答の確率を変えるのではなく、ゆっくり考えるパターンを引き出し得ることを示している。
主な貢献
- 本論文は、小さなRFTエキスパートと小さなアマチュアモデルの間のトークンレベルのロジット差を、より大きなベースモデルへの誘導として用いる、視覚推論転移のための単純なデコーディング時の定式化を導入する。
- ProxyThinkerは、小さな視覚推論器が、MathVista、MathVerse、MathVision、MMMU-Pro、R1-OneVisionBenchで評価された32Bおよび72Bの視覚言語モデルを含め、訓練なしに大幅に大きなモデルを改善できることを示している。
- 本手法は、7Bエキスパートによって誘導されたQwen2.5-VL-32Bベースモデルが、本論文で強調されたMathVisionの結果を含む一部のベンチマーク設定において、完全な32BのRFTモデルに匹敵するか、それをわずかに上回ることを可能にする。
- 振る舞いの分析は、ProxyThinkerが大規模モデルの下位目標計画能力と小さなエキスパートの自己検証および後戻りの傾向を組み合わせられることを実証している。
- vLLMベースの実装は複数のモデルを効率的に協調させ、従来のHuggingFace式のデコーディング時の誘導実装に対して38倍の高速化を報告しており、このアプローチをはるかに実用的なものにしている。
限界と注意点
- ProxyThinkerは、有用な小さなRFT視覚推論器とそれに対応するベースのアマチュアモデルへのアクセスを持つことに依存するため、今後の研究はこのレシピをより多くのモデルファミリーや公開されたエキスパートとアマチュアの組へと広げ得る。
- 本手法は推論時に複数のモデルを実行するため、単一モデルのベースラインと比較してシステムの複雑さを加える。本論文の最適化されたvLLM実装はこのオーバーヘッドを大幅に削減し、このアプローチが実用的であり得ることを示している。
- 性能の向上はベンチマークやエキスパートによって異なり、一部の設定では他より小さな改善を示す。この変動は、エキスパートの選択と誘導の強さを、今後のデコーディング時の推論システムにとって重要な調整つまみとして有用に特定している。
- 実験は確立された視覚的数学および複数分野にまたがるベンチマークに焦点を当てており、対話的、長期的、そして実世界の展開シナリオを、同じ誘導の発想に対する自然な次の検証として残している。
- ProxyThinkerは、モデルの基礎となる重みを変えるのではなくデコーディング時に推論の振る舞いを誘導しており、これはアクセス性とコストの面での利点である一方、今後の研究はそれが訓練時の手法をどのように補完するかを調べ得る。
この結果の読み解き方
本論文は、効率的な視覚推論への強力で実用的な貢献として読むのが最も適切である。すなわち、ProxyThinkerは、小さな訓練済みの推論器がテスト時にはるかに大きなモデルにおいてより優れたゆっくり考える振る舞いを引き出せることを示し、高価な完全規模の強化ファインチューニングに対する説得力のある代替手段ないし補完を提供している。