プレスリリース要約
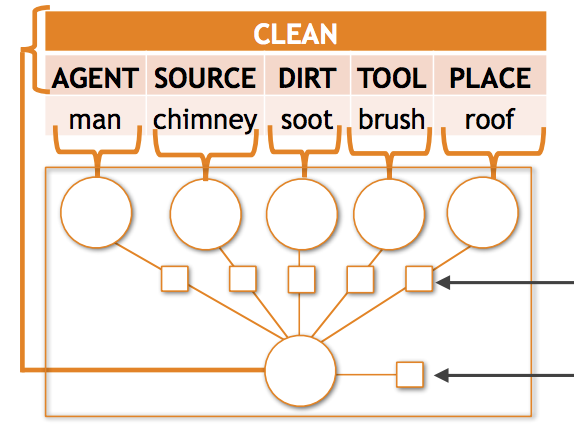
ワシントン大学とアレン人工知能研究所の研究者らは、コンピュータビジョンにおける手ごわい問題に取り組んだ。AIシステムが写真の中で起きていることを構造化された詳細で記述しようとするとき(「運ぶ」といった活動だけでなく、誰が運んでいるのか、何を運んでいるのか、どこで運んでいるのかも識別する)、シーンがオブジェクトと役割の珍しい組み合わせを含む場合には常に崩壊しがちである。研究チームは、imSituベンチマークデータセットにおいて、要求される予測のおよそ35パーセントが訓練中に10回未満しか見られなかったオブジェクト・役割の対応づけを含み、既存のモデルがまさにそうした場合に著しく精度を失うことを見いだした。これに対処するため、研究者らは2つの補完的な技術を開発した。第一に、条件付き確率場(Conditional Random Field)の枠組みに組み込まれた、合成テンソルポテンシャルと呼ばれる新しい数理モデルを設計した。これは異なる役割にまたがって名詞の共有表現を学習するもので、例えば「赤ちゃん」がどのように見えるかについての知識が、その赤ちゃんが運ばれている物として現れるか運んでいる人として現れるかにかかわらず、予測に寄与できるようにする。第二に、アノテーション付きの訓練状況を短いテキストのフレーズに変換し、それらのフレーズを用いてGoogle画像検索からおよそ500万枚の画像を取得し、限界尤度訓練と反復的な自己訓練を通じてノイズの多い結果を取り込む、意味的データ拡張パイプラインを構築した。両アプローチを組み合わせることで、従来の最先端に対してtop-5の動詞精度を約6パーセント、名詞・役割精度を10パーセント近く向上させ、本研究が特に対象とするまれな場合では相対的にさらに大きな向上が得られた。意味的スパース性(可能な出力の組み合わせが多すぎ、そのほとんどに対する事例が少なすぎること)は構造化された視覚的理解タスクにおいて広く存在する障害であり、本研究が、実際には現実世界でかなりありふれている珍しい状況に遭遇したときにAIシステムをより信頼できるものにするための具体的でスケーラブルな戦略を提供する点で、この知見は重要である。
要旨
意味的スパース性は、構造化された視覚分類問題における共通の課題である。出力空間が複雑な場合、可能な予測の大多数は、たとえあったとしても訓練セットでめったに見られない。本論文では、画像内で起きていることの構造化された要約(活動、オブジェクト、その活動内でオブジェクトが果たす役割を含む)を生成するタスクである状況認識における意味的スパース性を研究する。この問題について、ほとんどのオブジェクト・役割の組み合わせがまれであること、そして現在の最先端モデルがこのスパースなデータ領域で著しく性能を低下させることを経験的に見いだす。我々は、(1) 役割・名詞の組み合わせ間で事例を共有することを学習する新規のテンソル合成関数を導入すること、および (2) Web データを用いてまれにしか観測されない出力の自動収集した事例で訓練データを意味的に拡張すること、によってこうした多くの誤りを回避する。完全なCRFベースの構造化予測モデルに統合された場合、テンソルベースのアプローチは、top-5の動詞精度と名詞・役割精度において、それぞれ2.11%および4.40%の相対的改善で既存の最先端を上回る。我々の意味的拡張技術で500万枚の画像を追加すると、top-5の動詞精度と名詞・役割精度においてそれぞれさらに6.23%および9.57%の相対的改善が得られる。
引用
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}