ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
보도 자료 요약
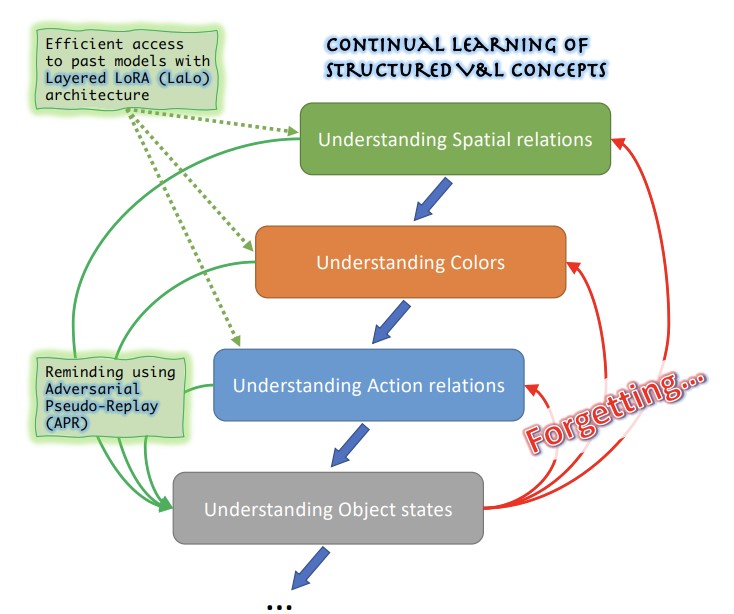
MIT-IBM Watson AI Lab, Georgia Tech, 라이스 대학교, IBM Research, 스탠퍼드 대학교의 연구진은 대규모 비전-언어 AI 모델의 실용적이지만 충분히 탐구되지 않은 문제를 다루었다. 이러한 시스템은 객체의 색상, 크기, 공간적 위치, 상태와 같은 미묘한 관계적·서술적 개념을 이해하는 데 어려움을 겪는 경향이 있으며, 엔지니어가 그러한 약점 하나를 새로운 데이터로 파인튜닝하여 고치려고 하면 모델이 이전에 교정된 약점을 처리하는 법을 잊어버리는 경향이 있는데, 이는 파국적 망각으로 알려진 현상이다. 상황은 각 문제를 식별하고 고치는 데 사용되는 데이터가 흔히 비공개이며 학습 라운드 전반에 걸쳐 보존되거나 재사용될 수 없다는 사실로 인해 더 어려워진다. 이를 다루기 위해, 연구팀은 이전 태스크 데이터에 대한 접근 없이, 그리고 테스트 시 어떤 유형의 개념이 평가되는지에 대한 어떠한 힌트도 없이 이러한 구조화된 시각-언어 개념의 연속 학습을 평가하도록 특별히 설계된 최초의 벤치마크인 ConStruct-VL을 만들었다. 이들은 또한 두 가지 상호 보완적인 기술적 기여를 개발하였다. 하나는 각 새로운 태스크마다 고정된 기본 모델 위에 경량의 저랭크 어댑터 모듈을 쌓는 Layered-LoRA(LaLo) 아키텍처로, 이는 시스템이 가중치를 다시 불러오지 않고도 학습 중 어떤 이전 태스크의 모델에든 효율적으로 접근할 수 있게 한다. 다른 하나는 그러한 과거 모델을 사용하여 까다로운 부정 학습 예시를 생성하는 Adversarial Pseudo-Replay(APR) 방법으로, 예컨대 텍스트 설명을 미묘하게 변경하여 짝지어진 이미지와 일치하지 않는 색상 단어를 포함시키며, 이는 현재 모델에게 이전에 학습한 것을 상기시키는 데 사용된다. Visual Genome 및 Visual Attributes in the Wild 데이터셋에서 가져온 여러 태스크 시퀀스에 걸쳐 BLIP 비전-언어 모델로 테스트한 결과, 결합된 접근법은 평균 망각을 약 5배 줄이고 최종 정확도를 최선의 경쟁 데이터 없는 연속 학습 방법 대비 최대 6.8 퍼센트 포인트 개선하였으며, 전체 모델 파라미터의 약 2.8 퍼센트만 사용하였다. 이러한 결과는 이전의 개선을 저하시키지 않으면서 프라이버시에 민감한 실세계 배포에서 AI 모델을 지속적으로 패치하는 실현 가능한 경로를 시사하기 때문에 중요하다.
초록
최근 대규모 사전학습 비전-언어(VL) 파운데이션 모델은 많은 제로샷 다운스트림 과제에서 놀라운 능력을 입증하며, 짧은 텍스트 프롬프트만으로 정의된 객체를 인식하는 데에 경쟁력 있는 결과를 달성하였다. 그러나 VL 모델은 객체의 속성, 상태, 객체 간 관계를 인식하는 능력과 같은 구조화된 VL 개념(SVLC) 추론에서는 여전히 취약하다는 것도 밝혀졌다. 이는 추론 오류로 이어지며, 이러한 오류는 발생할 때마다 VL 모델에 누락된 SVLC 기술을 가르쳐 교정해야 한다. 흔히 이는 문제가 발견된 비공개 데이터를 사용하여 이루어져야 하는데, 이는 자연스럽게 데이터 없는 연속(태스크 식별자 없는) VL 학습 환경으로 이어진다. 본 연구에서 우리는 최초의 Continual Data-Free Structured VL Concepts Learning(ConStruct-VL) 벤치마크를 소개하고, 이것이 기존의 많은 데이터 없는 연속 학습 전략에 어려운 과제임을 보인다. 따라서 우리는 과거 태스크 모델로부터 과거 태스크의 적대적 상기물을 생성하는 새로운 접근인 Adversarial Pseudo-Replay(APR)로 구성된 데이터 없는 방법을 제안한다. 이 방법을 효율적으로 사용하기 위해, 우리는 또한 학습 시 메모리 비용 없이 모든 과거 모델에 접근할 수 있게 하는 연속적이고 파라미터 효율적인 Layered-LoRA(LaLo) 신경망 아키텍처를 제안한다. 우리는 이 접근법이 모든 데이터 없는 방법을 최대 약 7%까지 능가하면서, 일부 수준의 experience-replay(데이터 프라이버시가 보존되어야 하는 응용에서는 금지됨)에 필적함을 보인다. 우리의 코드는 https://github.com/jamessealesmith/ConStruct-VL 에서 공개되어 있다.
세부 정보
인용
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}