ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Resumo do comunicado de imprensa
Pesquisadores da Rice University e do Google DeepMind desenvolveram um sistema de aprendizado visual autossupervisionado chamado ViC-MAE que treina um único modelo de IA para entender tanto imagens estáticas quanto vídeo sem exigir dados rotulados. O principal desafio que eles enfrentaram é que os modelos existentes tendem a ser bons em uma modalidade ou na outra, mas não em ambas — e, em particular, modelos treinados em vídeo historicamente têm dificuldade quando solicitados a ter bom desempenho em tarefas de imagem. Sua abordagem combina duas técnicas existentes: autoencoders mascarados, que treinam um modelo para reconstruir trechos da imagem ocultados aleatoriamente, e o aprendizado contrastivo, que treina um modelo para reconhecer que duas visões diferentes da mesma cena devem produzir representações semelhantes. A novidade é que, em vez de converter artificialmente imagens em vídeos falsos repetindo quadros — uma solução de contorno comum —, o ViC-MAE trata quadros amostrados com cerca de um segundo de diferença dentro de um vídeo real como "visões aumentadas" naturais da mesma cena, alimentando essas variações temporais no objetivo de aprendizado contrastivo enquanto ainda reconstrói quadros individuais com a perda de mascaramento. A equipe também descobriu que fazer o pooling de características locais de trechos em uma representação global, em vez de depender de um único token de classificação, ajudou a evitar que o modelo colapsasse durante o treinamento. Testada em benchmarks padrão, a versão ViT-Large do ViC-MAE alcançou 87,1% de acurácia top-1 no ImageNet e 75,9% no desafiador benchmark de vídeo Something-Something-v2, superando o método autossupervisionado comparável OmniMAE em cerca de 2,4 pontos percentuais no ImageNet, ao mesmo tempo em que também o superou em tarefas de vídeo — um resultado que sugere que dados de vídeo, usados criteriosamente, podem fortalecer de maneira significativa a compreensão de imagens sem sacrificar o desempenho em vídeo.
resumo
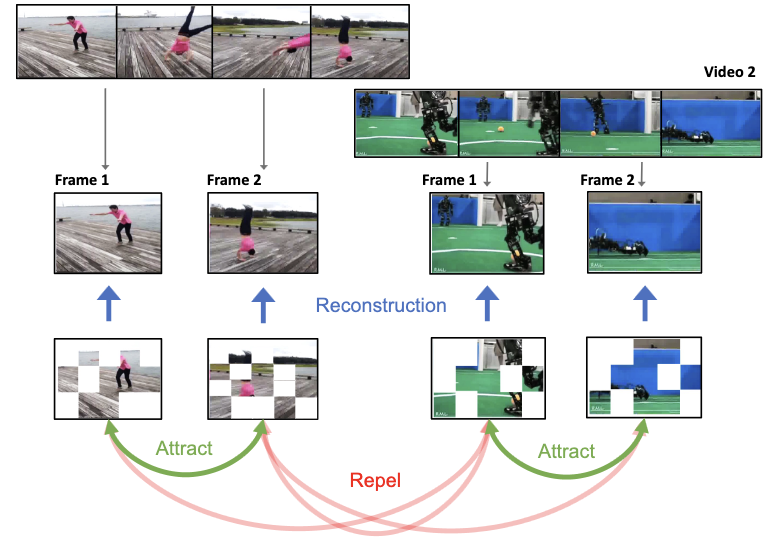
Propomos o ViC-MAE, um modelo que combina Masked AutoEncoders (MAE) e aprendizado contrastivo. O ViC-MAE é treinado usando uma característica global obtida por meio do pooling das representações locais aprendidas sob uma perda de reconstrução do MAE e aproveitando essa representação sob um objetivo contrastivo entre imagens e quadros de vídeo. Mostramos que as representações visuais aprendidas sob o ViC-MAE generalizam bem tanto para tarefas de classificação de vídeo quanto de imagem. Particularmente, o ViC-MAE obtém desempenho de aprendizado por transferência de vídeo para imagens no Imagenet-1k de estado da arte em comparação com o recém-proposto OmniMAE, alcançando uma acurácia top-1 de 86% (melhoria absoluta de +1,3%) quando treinado nos mesmos dados e 87,1% (melhoria absoluta de +2,4%) ao treinar com dados extras. Ao mesmo tempo, o ViC-MAE supera a maioria dos outros métodos em benchmarks de vídeo ao obter 75,9% de acurácia top-1 no desafiador benchmark de vídeo Something something-v2. Ao treinar com vídeos e imagens de uma combinação diversa de conjuntos de dados, nosso método mantém um desempenho equilibrado de aprendizado por transferência entre benchmarks de classificação de vídeo e de imagem, ficando apenas em segundo lugar, por pouco, em relação ao melhor método supervisionado.
detalhes
citação
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o ViC-MAE? O ViC-MAE é um método de aprendizado de representação visual autossupervisionado que combina autoencoding mascarado com aprendizado contrastivo, para que um único backbone possa aprender características úteis tanto para imagens quanto para vídeos.
- Como o ViC-MAE usa o vídeo de forma diferente dos métodos anteriores de pré-treinamento imagem-vídeo? Em vez de converter imagens em vídeos de quadros repetidos, o ViC-MAE trata quadros próximos de vídeos reais como aumentações temporais naturais e alinha suas representações agrupadas.
- Por que combinar modelagem de imagem mascarada e aprendizado contrastivo? O objetivo de reconstrução incentiva características locais de trechos robustas, enquanto o objetivo contrastivo incentiva a invariância global entre imagens aumentadas e quadros de vídeo deslocados temporalmente.
- Qual o papel do pooling no método? O ViC-MAE agrupa as características locais do ViT em uma representação global antes do ramo contrastivo, o que o artigo mostra ser importante para um treinamento estável e evita depender apenas de um token de classificação.
- Que evidências mostram que o ViC-MAE aprende representações equilibradas de imagem e vídeo? O artigo relata forte transferência para ImageNet, Kinetics-400, Places365, Something-Something-v2, vários conjuntos de dados de classificação de imagem downstream, e detecção e segmentação no COCO.
Principais contribuições
- O artigo introduz um framework autossupervisionado unificado que treina tanto a partir de imagens quanto de vídeos usando uma combinação de reconstrução mascarada e alinhamento contrastivo.
- O ViC-MAE mostra que quadros de vídeo podem servir como aumentações temporais eficazes para o aprendizado de representação no nível de imagem, melhorando a transferência de vídeo para imagem sem abrir mão do desempenho em vídeo.
- O método identifica o pooling global sobre características locais do MAE como uma escolha de projeto prática para o treinamento estável de autoencoders mascarados contrastivos.
- Com um backbone ViT-Large, o ViC-MAE atinge 87,1% de acurácia top-1 no ImageNet e 75,9% de acurácia top-1 no Something-Something-v2, superando bases autossupervisionadas comparáveis como o OmniMAE nas configurações relatadas.
- O artigo fornece ampla validação empírica em classificação de imagem, reconhecimento de ações em vídeo, detecção de objetos e segmentação, tornando a contribuição útil além de um único benchmark.
Limitações e ressalvas
- Os resultados mais fortes usam backbones ViT grandes e pré-treinamento com múltiplos conjuntos de dados, o que é típico do aprendizado de representação visual moderno em estilo de modelo fundacional e ajuda a evidenciar o comportamento de escalabilidade do método.
- O ViC-MAE é avaliado principalmente por meio de benchmarks de transferência e ajuste fino, em vez de todas as possíveis tarefas downstream de vídeo ou imagem, deixando domínios adicionais como avaliações de acompanhamento promissoras.
- A abordagem depende de um equilíbrio cuidadoso entre os objetivos de reconstrução e contrastivo, mas o artigo inclui ablações sobre pooling, separação de quadros, aumentações e mistura de dados que tornam as escolhas de projeto claras.
- O método aprimora a autossupervisão unificada de imagem e vídeo, embora modelos supervisionados específicos para tarefas ainda possam ser competitivos em alguns benchmarks individuais; isso enquadra o ViC-MAE como um forte aprendiz de representação geral, e não como um especialista restrito.
- O artigo concentra-se em pré-treinamento somente visual, de modo que extensões para texto, áudio ou alinhamento multimodal mais amplo permanecem como oportunidades naturais com base no mesmo framework.
Como interpretar este resultado
Este artigo é melhor compreendido como um avanço robusto e prático no aprendizado autossupervisionado de representação de imagem e vídeo: o ViC-MAE demonstra que dados de vídeo podem melhorar as representações de imagem preservando um excelente desempenho em vídeo, e o faz com uma combinação elegante de autoencoding mascarado, aprendizado contrastivo temporal e características locais agrupadas.