ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Resumo do comunicado de imprensa
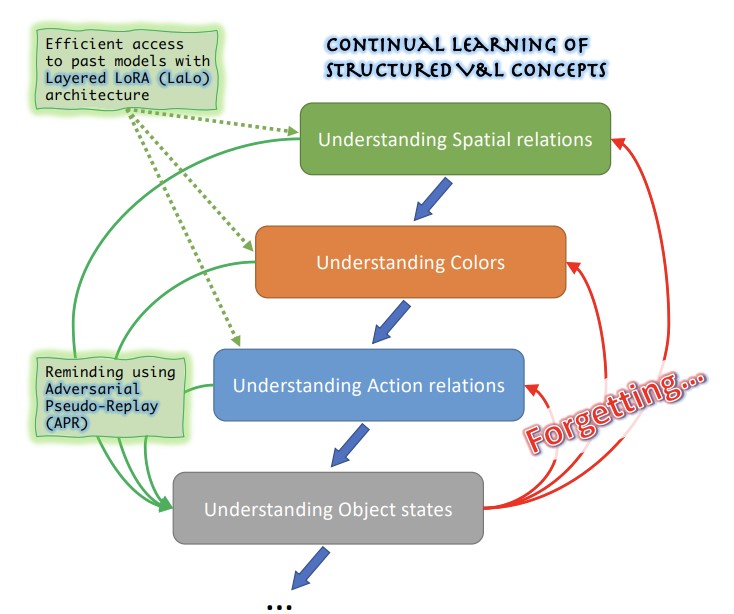
Pesquisadores do MIT-IBM Watson AI Lab, da Georgia Tech, da Rice University, da IBM Research e de Stanford enfrentaram um problema prático, mas pouco explorado, dos grandes modelos de IA de visão-e-linguagem: esses sistemas tendem a ter dificuldade em compreender conceitos relacionais e descritivos sutis — como cores, tamanhos, posições espaciais e estados dos objetos — e, quando os engenheiros tentam corrigir uma dessas deficiências ajustando o modelo com novos dados, o modelo tende a esquecer como lidar com deficiências corrigidas anteriormente, um fenômeno conhecido como esquecimento catastrófico. A situação é agravada pelo fato de que os dados usados para identificar e corrigir cada problema costumam ser privados e não podem ser retidos ou reutilizados entre as rodadas de treinamento. Para resolver isso, a equipe criou o ConStruct-VL, o primeiro benchmark projetado especificamente para avaliar o aprendizado contínuo desses conceitos estruturados de visão-linguagem sem acesso aos dados de tarefas anteriores e sem nenhuma pista, no momento do teste, sobre qual tipo de conceito está sendo avaliado. Eles também desenvolveram duas contribuições técnicas complementares: uma arquitetura Layered-LoRA (LaLo), que empilha módulos adaptadores leves e de baixo posto sobre um modelo base congelado para cada nova tarefa, permitindo que o sistema acesse eficientemente o modelo de qualquer tarefa anterior durante o treinamento sem recarregar os pesos; e um método de Pseudo-Replay Adversarial (APR), que usa esses modelos passados para gerar exemplos de treinamento negativos difíceis — por exemplo, alterando sutilmente uma descrição textual para incluir uma palavra de cor inconsistente com a imagem associada — que são então usados para lembrar ao modelo atual o que ele havia aprendido antes. Testada no modelo de visão-linguagem BLIP em várias sequências de tarefas extraídas dos conjuntos de dados Visual Genome e Visual Attributes in the Wild, a abordagem combinada reduziu o esquecimento médio em cerca de cinco vezes e melhorou a acurácia final em até 6,8 pontos percentuais em comparação com os melhores métodos concorrentes de aprendizado contínuo sem dados, usando apenas cerca de 2,8 por cento dos parâmetros do modelo completo — resultados importantes porque sugerem um caminho viável para corrigir continuamente modelos de IA em implantações reais sensíveis à privacidade sem degradar melhorias anteriores.
resumo
Recentemente, modelos de fundação de Visão-e-Linguagem (VL) pré-treinados em larga escala demonstraram capacidades notáveis em muitas tarefas downstream zero-shot, alcançando resultados competitivos no reconhecimento de objetos definidos por prompts de texto tão curtos quanto algumas palavras. No entanto, também foi demonstrado que os modelos VL ainda são frágeis no raciocínio sobre Conceitos VL Estruturados (SVLC), como a capacidade de reconhecer atributos, estados e relações entre objetos. Isso leva a erros de raciocínio, que precisam ser corrigidos à medida que ocorrem, ensinando aos modelos VL as habilidades de SVLC ausentes; muitas vezes isso precisa ser feito usando dados privados onde o problema foi encontrado, o que naturalmente leva a um cenário de aprendizado VL contínuo sem dados (sem task-id). Neste trabalho, introduzimos o primeiro benchmark de Aprendizado Contínuo de Conceitos VL Estruturados sem Dados (ConStruct-VL) e mostramos que ele é desafiador para muitas estratégias existentes de aprendizado contínuo (CL) sem dados. Propomos, portanto, um método sem dados composto por uma nova abordagem de Pseudo-Replay Adversarial (APR), que gera lembretes adversariais de tarefas passadas a partir dos modelos dessas tarefas. Para usar esse método de forma eficiente, também propomos uma arquitetura neural contínua e eficiente em parâmetros chamada Layered-LoRA (LaLo), que permite acesso a todos os modelos passados sem custo de memória no momento do treinamento. Mostramos que essa abordagem supera todos os métodos sem dados em até cerca de 7%, chegando inclusive a igualar alguns níveis de experience-replay (proibitivo para aplicações em que a privacidade dos dados precisa ser preservada). Nosso código está disponível publicamente em https://github.com/jamessealesmith/ConStruct-VL
detalhes
citação
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}