AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
News Release Summary
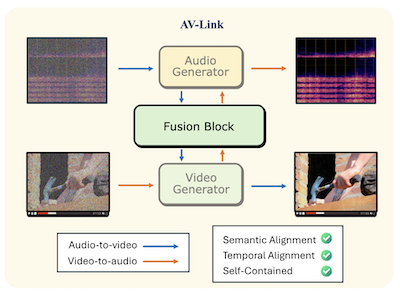
Researchers from Rice University and Snap Inc. have developed a system called AV-Link that can generate synchronized audio from silent video, or generate video to match a given audio clip, using a single unified framework rather than the separate specialized tools that have dominated this field. The core problem the team tackled is temporal alignment — getting the generated output to actually sync up with events in the source material, so that, for instance, a drumbeat lands precisely when a drumstick hits, rather than just sounding vaguely drum-like. Most existing approaches rely on pretrained feature extractors like CLIP or ImageBind to pull semantic meaning from one modality and feed it to a generator for the other, but these extractors were never designed with tight timing in mind. Instead, AV-Link taps directly into the internal activations of frozen, pretrained audio and video diffusion models, which the researchers found to already contain rich temporal information as a byproduct of learning to generate time-varying signals. A lightweight module called a Fusion Block — adding roughly 186 million parameters on top of the frozen base models — connects the two generators through a shared self-attention operation with a specially designed rotary position embedding that aligns audio and video tokens to the same temporal reference frame. On the standard VGGSounds benchmark, the system improved onset accuracy, a measure of how well sound events line up with visual events, by up to 76 percent over the best competing baseline, and in user studies it was preferred over Meta's much larger MovieGen Audio model for temporal alignment 63.6 percent of the time. The practical significance is that a single compact system could handle text-to-audio, text-to-video, video-to-audio, and audio-to-video generation, potentially simplifying production pipelines for applications ranging from automated film post-production to AI-generated media.
abstract
We propose AV-Link, a unified framework for Video-to-Audio (A2V) and Audio-to-Video (A2V) generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that facilitates bidirectional information exchange between video and audio diffusion models through temporally-aligned self attention operations. Unlike prior work that uses dedicated models for A2V and V2A tasks and relies on pretrained feature extractors, AV-Link achieves both tasks in a single self-contained framework, directly leveraging features obtained by the complementary modality (i.e. video features to generate audio, or audio features to generate video). Extensive automatic and subjective evaluations demonstrate that our method achieves a substantial improvement in audio-video synchronization, outperforming more expensive baselines such as the MovieGen video-to-audio model.
details
citation
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}