Improved Visual Grounding through Self-Consistent Explanations
News Release Summary
Researchers at Rice University and UC Irvine have developed a technique to help AI systems more reliably pinpoint the location of objects in images when given a text description — a task known as visual grounding. The core problem they tackled is that existing vision-language models, which learn to match images with text, can correctly locate an object like a "frisbee" but fail when the same object is described using a different word, like "disc." To fix this, the team created a training approach called SelfEQ (Self-consistency EQuivalence Tuning), which uses a large language model to automatically generate paraphrases for image captions and then fine-tunes the visual model so that both the original phrase and its paraphrase produce the same highlighted region in the image. The method works without requiring any bounding box annotations, relying instead on gradient-based visual explanation maps — specifically GradCAM — as a form of weak supervision. Tested on three standard benchmarks, SelfEQ improved localization accuracy by 4.69 percentage points on Flickr30k, 7.68 points on ReferIt, and an average of 3.74 points on RefCOCO+, beating most other methods that also skip bounding box supervision and even rivaling some that use it. The practical upshot is a model that handles a broader vocabulary and localizes objects more consistently — useful progress for applications like visual search and human-machine interaction that depend on connecting language to specific parts of an image.
abstract
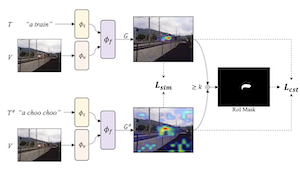
Vision-and-language models trained to match images with text can be combined with visual explanation methods to point to the locations of specific objects in an image. Our work shows that the localization --"grounding"-- abilities of these models can be further improved by finetuning for self-consistent visual explanations. We propose a strategy for augmenting existing text-image datasets with paraphrases using a large language model, and SelfEQ, a weakly-supervised strategy on visual explanation maps for paraphrases that encourages self-consistency. Specifically, for an input textual phrase, we attempt to generate a paraphrase and finetune the model so that the phrase and paraphrase map to the same region in the image. We posit that this both expands the vocabulary that the model is able to handle, and improves the quality of the object locations highlighted by gradient-based visual explanation methods (e.g. GradCAM). We demonstrate that SelfEQ improves performance on Flickr30k, ReferIt, and RefCOCO+ over a strong baseline method and several prior works. Particularly, comparing to other methods that do not use any type of box annotations, we obtain 84.07% on Flickr30k (an absolute improvement of 4.69%), 67.40% on ReferIt (an absolute improvement of 7.68%), and 75.10%, 55.49% on RefCOCO+ test sets A and B respectively (an absolute improvement of 3.74% on average).
details
citation
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What problem does SelfEQ address? SelfEQ improves visual grounding by making a vision-language model localize equivalent phrases, such as "frisbee" and "disc," to the same image region.
- How does the method work without bounding-box supervision? It uses GradCAM explanation maps from an existing vision-language model as weak supervision, then trains the model so an original phrase and its paraphrase produce consistent localization maps.
- Why are LLM-generated paraphrases useful here? The paraphrases expand the wording the model can handle and create equivalence pairs that teach the model to ground semantically similar descriptions consistently.
- What is the role of the SelfEQ objective? The objective combines heatmap similarity with a region-of-interest consistency term so paraphrased prompts align spatially while avoiding trivial uniform explanation maps.
- Which benchmarks show the method's impact? The paper reports improvements on Flickr30k, ReferIt, and RefCOCO+, including strong results among methods that do not use box annotations.
Main contributions
- The paper introduces Self-consistency EQuivalence Tuning, a weakly supervised objective for improving visual grounding through consistent explanations across paraphrased text.
- It shows that LLM-generated paraphrases can be used as scalable training signals for visual grounding, turning linguistic equivalence into useful spatial supervision.
- The method improves an ALBEF-based grounding pipeline without requiring bounding boxes, segmentation masks, object detectors, or box proposal networks.
- SelfEQ achieves substantial gains over strong weakly supervised baselines, including 84.07% on Flickr30k, 67.40% on ReferIt, and improved RefCOCO+ pointing-game accuracy.
- The ablations clarify why explicit equivalence tuning matters: simply adding paraphrases as extra image-text pairs is less effective than directly enforcing self-consistent visual explanations.
Limitations and cautions
- SelfEQ is designed for weakly supervised grounding with explanation maps, so it complements rather than replaces fully supervised grounding systems when high-quality boxes are available.
- The method depends on the quality of generated paraphrases, but the paper uses a clear prompting and filtering strategy and shows that the resulting equivalence pairs provide practical gains.
- Because it builds on GradCAM-style explanations from a base vision-language model, performance can reflect the strengths of the underlying model; this makes SelfEQ especially valuable as a tuning strategy for improving existing models.
- The evaluation centers on standard grounding benchmarks and pointing-game accuracy, leaving broader real-world visual search, robotics, and accessibility settings as natural next applications.
- The approach focuses on phrase and region grounding rather than full open-ended visual reasoning, which keeps the contribution well targeted and makes the reported gains easier to interpret.
How to read this result
This paper is best read as a strong contribution to weakly supervised visual grounding: SelfEQ turns paraphrase consistency into a practical training signal, improving localization accuracy and vocabulary robustness without needing expensive object-location annotations.