Estimating and Maximizing Mutual Information for Knowledge Distillation
News Release Summary
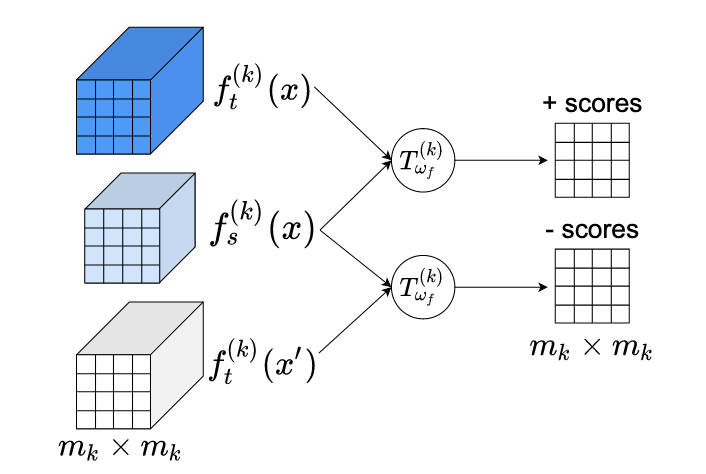
Researchers at the University of Virginia and Rice University have developed a new technique for shrinking large artificial intelligence models down to sizes that can run on phones and other resource-limited devices, without sacrificing too much of their accuracy. The core challenge in this field, known as knowledge distillation, is getting a smaller "student" neural network to absorb useful information from a larger, more capable "teacher" network. Existing methods typically do this by matching the outputs or intermediate representations of the two networks using simple distance metrics, which can struggle when the teacher and student have very different internal architectures. The new framework, called MIMKD (Mutual Information Maximization Knowledge Distillation), takes a different approach by using a contrastive learning objective rooted in information theory — specifically, a Jensen-Shannon divergence-based estimator — to simultaneously estimate and maximize the mutual information shared between the two networks' representations, both at the level of final global features and at finer-grained local and intermediate feature levels. A practical advantage is that this formulation, unlike competing methods such as Contrastive Representation Distillation, requires only a single negative sample during training rather than thousands, making it far less memory-intensive and more applicable to intermediate network layers. In tests on the CIFAR-100 and ImageNet image classification benchmarks, MIMKD consistently outperformed established alternatives across a wide range of teacher-student pairings, including cases where the two networks had very different designs, lifting a ShuffleNetV2's accuracy by nearly 5 percentage points using a ResNet-50 teacher and improving a ResNet-18 on ImageNet by 1.44 percentage points over its baseline — results that suggest the approach could help make capable AI models more practical to deploy at the edge.
abstract
In this work, we propose Mutual Information Maximization Knowledge Distillation (MIMKD). Our method uses a contrastive objective to simultaneously estimate and maximize a lower bound on the mutual information of local and global feature representations between a teacher and a student network. We demonstrate through extensive experiments that this can be used to improve the performance of low capacity models by transferring knowledge from more performant but computationally expensive models. This can be used to produce better models that can be run on devices with low computational resources. Our method is flexible, we can distill knowledge from teachers with arbitrary network architectures to arbitrary student networks. Our empirical results show that MIMKD outperforms competing approaches across a wide range of student-teacher pairs with different capacities, with different architectures, and when student networks are with extremely low capacity. We are able to obtain 74.55% accuracy on CIFAR100 with a ShufflenetV2 from a baseline accuracy of 69.8% by distilling knowledge from ResNet-50. On Imagenet we improve a ResNet-18 network from 68.88% to 70.32% accuracy (1.44%+) using a ResNet-34 teacher network.
citation
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}