Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
News Release Summary
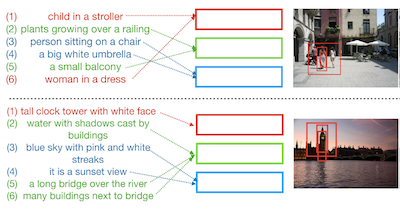
Researchers at the University of Virginia and IBM Research have developed a system called Drill-down that lets users find specific images by typing a series of natural language descriptions, each one narrowing the search further rather than trying to capture everything in a single query. The problem they were tackling is a familiar one: existing image search tools struggle when a user wants to locate a very particular photo of a complex scene containing multiple objects, because cramming an entire scene description into one sentence is both difficult and imprecise. Instead of forcing that single-shot approach, Drill-down lets users start broad — say, "a group of people posing in a park" — and progressively add more specific details across several turns, such as "there is a bride among them," with the system updating its results each time. The key technical contribution is a compact set of state vectors that store and organize the history of a user's queries, with each vector learning to track a distinct part of the scene rather than collapsing everything into one representation, which is how earlier dialogue-based retrieval systems worked. Crucially, the team found they could train the model without collecting expensive human-annotated search sessions, instead using existing image region captions from the Visual Genome dataset as a cheap substitute for real user queries. Tests on both simulated and real human users showed that Drill-down outperformed competing methods while actually using less memory and fewer parameters, and more than 80 percent of human testers successfully located their target image within five turns. The work suggests that breaking image search into a conversational back-and-forth is a practical path toward retrieving highly specific images in large, diverse collections.
abstract
This paper explores the task of interactive image retrieval using natural language queries, where a user progressively provides input queries to refine a set of retrieval results. Moreover, our work explores this problem in the context of complex image scenes containing multiple objects. We propose Drill-down, an effective framework for encoding multiple queries with an efficient compact state representation that significantly extends current methods for single-round image retrieval. We show that using multiple rounds of natural language queries as input can be surprisingly effective to find arbitrarily specific images of complex scenes. Furthermore, we find that existing image datasets with textual captions can provide a surprisingly effective form of weak supervision for this task. We compare our method with existing sequential encoding and embedding networks, demonstrating superior performance on two proposed benchmarks: automatic image retrieval on a simulated scenario that uses region captions as queries, and interactive image retrieval using real queries from human evaluators.
details
citation
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}