Text2Scene: Generating Compositional Scenes from Textual Descriptions
News Release Summary
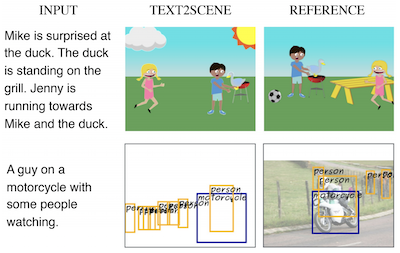
Researchers at the University of Virginia and IBM's Thomas J. Watson Research Center have developed a system called Text2Scene that can automatically generate visual scenes from written descriptions — without relying on the Generative Adversarial Networks, or GANs, that most competing approaches depend on. Rather than trying to synthesize an entire image at once, the system works more like a careful illustrator, reading a sentence and then placing objects one at a time onto a blank canvas, deciding at each step what to add next, where to put it, and what it should look like. The model uses attention mechanisms to focus on different parts of the input text as it builds the scene, so when a description says "Jenny is running towards Mike," the system can figure out that Jenny's orientation depends on where Mike is already standing. The team tested their approach across three quite different tasks — generating cartoon clip-art scenes, predicting realistic object layout maps, and assembling composite photographs from retrieved image patches — using the same underlying framework with only minor modifications for each. In head-to-head comparisons, Text2Scene matched or beat GAN-based rivals on most automatic quality metrics and outperformed all of them, including the strong AttnGAN model, when human evaluators judged which images better matched their captions. The work is notable both because it sidesteps the notoriously finicky GAN training process and because it produces interpretable, step-by-step outputs that make it easier to understand why the model made the choices it did — a quality that purely pixel-based generation systems generally lack.
abstract
In this paper, we propose Text2Scene, a model that generates various forms of compositional scene representations from natural language descriptions. Unlike recent works, our method does NOT use Generative Adversarial Networks (GANs). Text2Scene instead learns to sequentially generate objects and their attributes (location, size, appearance, etc) at every time step by attending to different parts of the input text and the current status of the generated scene. We show that under minor modifications, the proposed framework can handle the generation of different forms of scene representations, including cartoon-like scenes, object layouts corresponding to real images, and synthetic images. Our method is not only competitive when compared with state-of-the-art GAN-based methods using automatic metrics and superior based on human judgments but also has the advantage of producing interpretable results.
details
citation
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}