ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
News Release Summary
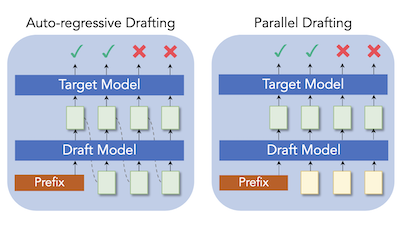
Researchers at Rice University and Tencent AI Lab have developed a new technique called ParallelSpec that speeds up a popular method for making large language model inference faster. The underlying challenge is that so-called speculative decoding systems — which use a small "draft" model to quickly propose candidate text that a larger target model then checks in parallel — still force that small drafter to generate tokens one at a time, creating a bottleneck that grows longer the more tokens the drafter is asked to predict. To fix this, the team built a single lightweight draft model that predicts multiple future tokens simultaneously in one forward pass, using specially trained placeholder "mask" tokens to prompt the model to look ahead without running sequentially. They also designed a careful training procedure, called group-wise parallel training, to prevent mismatches between how the model is trained and how it actually runs at inference time. When plugged into two established speculative decoding frameworks, Medusa and EAGLE, the approach delivered consistent speed gains across a range of text generation tasks including translation, summarization, math reasoning, and question answering; on Llama-2-13B it reached 2.84 times the speed of standard autoregressive generation, and it lifted Medusa's speedup on Vicuna-7B by roughly 63 percent. The work matters because it addresses a fundamental inefficiency in the drafting stage rather than simply tuning how many tokens get proposed, potentially making lossless LLM acceleration more practical for real-time applications.
abstract
Speculative decoding has proven to be an efficient solution to large language model (LLM) inference, where the small drafter predicts future tokens at a low cost, and the target model is leveraged to verify them in parallel. However, most existing works still draft tokens auto-regressively to maintain sequential dependency in language modeling, which we consider a huge computational burden in speculative decoding. We present ParallelSpec, an alternative to auto-regressive drafting strategies in state-of-the-art speculative decoding approaches. In contrast to auto-regressive drafting in the speculative stage, we train a parallel drafter to serve as an efficient speculative model. ParallelSpec learns to efficiently predict multiple future tokens in parallel using a single model, and it can be integrated into any speculative decoding framework that requires aligning the output distributions of the drafter and the target model with minimal training cost. Experimental results show that ParallelSpec accelerates baseline methods in latency up to 62% on text generation benchmarks from different domains, and it achieves 2.84X overall speedup on the Llama-2-13B model using third-party evaluation criteria.
details
citation
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}