Evolving Image Compositions for Feature Representation Learning
Краткое изложение пресс-релиза
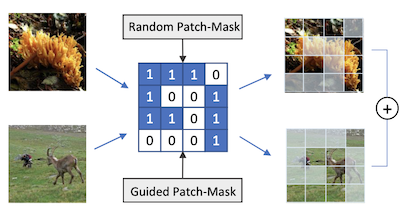
Исследователи из University of Virginia и Rice University разработали технику аугментации данных под названием PatchMix, которая помогает нейронным сетям распознавания изображений учиться лучше за счёт обучения на искусственно сконструированных гибридных изображениях. Основная проблема в том, что модели deep learning для визуального распознавания склонны переобучаться на своих обучающих данных, и хотя существующие методы, такие как Mixup и CutMix, уже смешивают пары изображений для борьбы с этим, они ограничены в том, насколько гибко они могут комбинировать эти изображения. PatchMix решает это, разрезая два изображения на сетку патчей одинакового размера и обменивая патчи между ними согласно бинарной маске, а затем присваивая результирующему составному изображению смешанную метку, пропорциональную тому, сколько патчей пришло из каждого источника. Команда также добавила вторичную функцию потерь, которая обучает сеть правильно определять, к какому классу принадлежит каждый отдельный патч, а не только изображение в целом, что вынуждает модель строить более локально осведомлённые представления. Идя дальше, исследователи использовали генетический алгоритм поиска для автоматического обнаружения того, какие пары категорий изображений наиболее полезно смешивать вместе и какие сеточные паттерны производят наиболее сложные — и потому наиболее информативные — обучающие примеры, всё это без необходимости переобучать модель с нуля для каждой кандидатной конфигурации. Протестированная на стандартных бенчмарках, модель ResNet-50, обученная с PatchMix, превзошла базовые модели на CIFAR-10, CIFAR-100, Tiny ImageNet и ImageNet и показала более сильную производительность transfer learning на задачах, включая детекцию объектов, распознавание сцен и генерацию подписей к изображениям, что говорит о том, что метод производит более универсальные визуальные признаки, чем конкурирующие подходы.
аннотация
Свёрточные нейронные сети для визуального распознавания требуют больших объёмов обучающих образцов и обычно выигрывают от аугментации данных. В этой статье предлагается PatchMix — метод аугментации данных, который создаёт новые образцы путём составления патчей из пар изображений в сеточном паттерне. Этим новым образцам присваиваются метки-оценки, пропорциональные числу патчей, заимствованных из каждого изображения. Затем мы добавляем набор дополнительных функций потерь на уровне патчей для регуляризации и для поощрения хороших представлений как на уровне патчей, так и на уровне изображений. Модель ResNet-50, обученная на ImageNet с использованием PatchMix, демонстрирует превосходные способности к transfer learning на широком спектре бенчмарков. Хотя PatchMix может полагаться на случайные пары и случайные сеточные паттерны для смешивания, мы исследуем эволюционный поиск как направляющую стратегию для совместного обнаружения оптимальных сеточных паттернов и пар изображений. С этой целью мы разрабатываем функцию приспособленности, которая обходит необходимость переобучать модель для оценки каждого возможного выбора. Таким образом, PatchMix превосходит базовую модель на CIFAR-10 (+1,91), CIFAR-100 (+5,31), Tiny Imagenet (+3,52) и ImageNet (+1,16).
подробности
цитирование
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}