Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Краткое изложение пресс-релиза
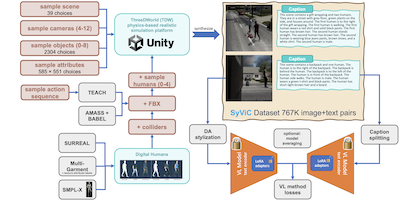
Исследователи из MIT, IBM, Rice University и нескольких других учреждений выявили и сделали практический шаг к устранению устойчивого «слепого пятна» в популярных моделях зрения и языка на основе искусственного интеллекта, таких как CLIP: эти системы удивительно плохо понимают что-либо помимо объектов на изображении, с трудом улавливая атрибуты, пространственные отношения, действия и порядок слов так, как это легко даётся людям. Чтобы решить эту проблему, команда создала синтетический набор данных из миллиона изображений под названием SyViC — Synthetic Visual Concepts — запуская физические 3D-симуляции в движке ThreeDWorld, наполняя сцены случайными объектами, материалами и анимированными человеческими аватарами, одетыми в разнообразную одежду, а затем автоматически генерируя подробные текстовые подписи из метаданных сцены. Ключевая идея состоит в том, что синтетические среды позволяют исследователям дёшево создавать пары изображение-текст, которые намеренно подчёркивают именно те концепты, не являющиеся существительными, которые модели упускают, — нечто, что чрезмерно сложно и дорого делать с реальными фотографиями. Когда они дообучили CLIP и CyCLIP на SyViC, используя сочетание низкоранговой адаптации параметров (LoRA), доменной адаптации на основе переноса стиля и техники разбиения подписей для обработки более длинного описательного текста, модели улучшились до 9,9% на бенчмарке композиционального рассуждения ARO и на 4,3% на оценке VL-Checklist, пожертвовав при этом менее чем одним процентом своей zero-shot точности классификации по 21 задаче. Эта работа важна, поскольку она демонстрирует, что целенаправленные синтетические данные, без каких-либо реальных изображений, могут существенно компенсировать хорошо задокументированную структурную слабость в контрастивном обучении моделей зрения и языка, и команда опубликовала как набор данных, так и код в открытом доступе.
аннотация
Крупномасштабные предобученные модели зрения и языка (VL) продемонстрировали выдающуюся производительность во многих приложениях, позволяя заменить фиксированный набор поддерживаемых классов на zero-shot рассуждение с открытым словарём над (почти произвольными) запросами на естественном языке. Однако недавние работы выявили фундаментальную слабость этих моделей. Например, их трудности с пониманием визуально-языковых концептов (VLC), которые выходят «за пределы существительных», таких как значение слов, не обозначающих объекты (например, атрибутов, действий, отношений, состояний и т. д.), или трудности с выполнением композиционального рассуждения, такого как понимание значимости порядка слов в предложении. В этой работе мы исследуем, в какой степени чисто синтетические данные можно использовать, чтобы научить эти модели преодолевать такие недостатки без ущерба для их zero-shot возможностей. Мы предлагаем Synthetic Visual Concepts (SyViC) — синтетический набор данных масштаба миллиона и кодовую базу для генерации данных, позволяющую генерировать дополнительные подходящие данные для улучшения понимания VLC и композиционального рассуждения VL-моделей. Кроме того, мы предлагаем общую стратегию дообучения VL для эффективного использования SyViC с целью достижения этих улучшений. Наши обширные эксперименты и абляционные исследования на бенчмарках VL-Checklist, Winoground и ARO демонстрируют, что можно адаптировать сильные предобученные VL-модели с помощью синтетических данных, значительно повышая их понимание VLC (например, на 9,9% на ARO и на 4,3% на VL-Checklist) при падении их zero-shot точности менее чем на 1%.
подробности
цитирование
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}