Taming Data and Transformers for Audio Generation
Краткое изложение пресс-релиза
Исследователи из Rice University и Snap Inc. справились с устойчивым узким местом в ИИ-генерации фоновых звуков (ambient sound) — нехваткой больших, хорошо размеченных обучающих данных и моделей, которые не улучшаются по мере роста. Чтобы решить проблему данных, команда разработала автоматизированный конвейер, который извлекает клипы фонового аудио из существующих видеонаборов на основе YouTube, выявляя сегменты, где отсутствует транскрипция речи или музыки, что позволяет обойтись без загрузки и запуска дорогостоящих классификаторов на исходном видео. Результатом стал AutoReCap-XL — набор данных из 47 миллионов клипов фонового аудио с текстовыми описаниями, примерно в 75 раз больший, чем то, что было доступно ранее. Для генерации этих описаний они построили AutoCap — модель описания аудио, которая включает модуль Q-Former наряду с визуальными метаданными, такими как названия видео и описания на уровне кадров, достигая показателя CIDEr 83,2 на стандартном бенчмарке AudioCaps — на 3,2% выше, чем у прежних методов. Со стороны генерации они представили GenAu — диффузионную модель на основе трансформера, масштабированную до 1,25 миллиарда параметров, которая заимствует архитектуру "FIT", изначально разработанную для видео, используя локальные и глобальные слои внимания, чтобы сосредоточить вычисления на информативных аудиосегментах, а не распределять их равномерно по тихим или избыточным фрагментам. По сравнению с сопоставимыми базовыми моделями GenAu улучшил Inception Score на 11,1%, Fréchet Audio Distance на 4,7% и показатель согласованности с текстом CLAP на 13,5% и — в отличие от прежних больших аудиомоделей — продолжал стабильно улучшаться по мере роста как размера модели, так и размера набора данных, что наводит на мысль, что у области наконец может появиться рецепт масштабирования генерации фоновых звуков так же, как уже масштабированы генерация изображений и видео.
аннотация
Масштабируемость генераторов фоновых звуков (ambient sound) сдерживается дефицитом данных, недостаточным качеством описаний и ограниченной масштабируемостью архитектуры модели. Эта работа решает эти проблемы, продвигая масштабирование как данных, так и моделей. Во-первых, мы предлагаем эффективный и масштабируемый конвейер сбора набора данных, специально предназначенный для генерации фонового аудио, результатом которого стал AutoReCap-XL — крупнейший набор данных аудио-текст для фоновых звуков, содержащий более 47 миллионов клипов. Чтобы обеспечить высококачественные текстовые аннотации, мы предлагаем AutoCap — высококачественную модель автоматического описания аудио. Используя модуль Q-Former и метаданные аудио, AutoCap существенно повышает качество описаний, достигая показателя CIDEr $83.2$, что на $3.2\%$ выше, чем у предыдущих моделей описания. Наконец, мы предлагаем GenAu — масштабируемую архитектуру генерации аудио на основе трансформера, которую мы масштабируем до 1,25 млрд параметров. Мы демонстрируем её преимущества от масштабирования данных с синтетическими описаниями, а также от масштабирования размера модели. По сравнению с базовыми генераторами аудио, обученными при схожем размере и масштабе данных, GenAu получает значительные улучшения: $4.7\%$ по показателю FAD, $11.1\%$ по IS и $13.5\%$ по показателю CLAP. Наш код, контрольные точки модели и набор данных общедоступны.
подробности
цитирование
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Какую проблему решает эта статья? Она устраняет основные препятствия для масштабируемой генерации фоновых звуков: дефицит данных аудио-текст, слабое качество описаний и архитектуры генераторов, которые не получали надёжной выгоды от масштабирования.
- Что такое AutoReCap-XL? AutoReCap-XL — это очень большой набор данных аудио-текст для фоновых звуков, содержащий более 47 миллионов клипов, собранных путём фильтрации сегментов онлайн-видео на предмет аудио без речи и музыки и их автоматического переописания.
- Что такое AutoCap? AutoCap — это модель автоматического описания аудио, которая объединяет аудиопризнаки, Q-Former, декодирование BART и метаданные, такие как названия видео и визуальные описания, для получения более качественных описаний аудио.
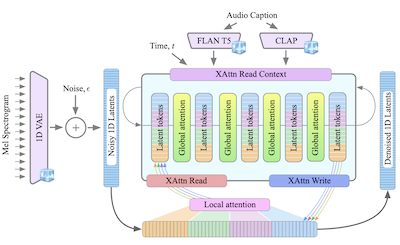
- Что такое GenAu? GenAu — это латентная диффузионная модель на основе трансформера для генерации аудио из текста, которая адаптирует архитектуру в стиле FIT с локальным и глобальным вниманием к временной структуре аудио.
- Почему масштабирование важно в этой работе? Статья показывает, что GenAu улучшается как с увеличением объёма синтетически описанных данных, так и с ростом размера модели, что важно, поскольку более ранние генераторы фонового аудио часто демонстрировали слабое или непостоянное поведение при масштабировании.
Основные вклады
- Статья представляет AutoReCap-XL, описанный как крупнейший в работе набор данных аудио-текст для фоновых звуков, содержащий 47 миллионов клипов и примерно 123,5 тыс. часов аудио, извлечённых из крупномасштабных видеоисточников.
- Она предлагает AutoCap — сильную модель описания аудио, которая использует Q-Former и метаданные для повышения качества описаний, достигая показателя CIDEr 83,2 на AudioCaps.
- Она представляет GenAu — масштабируемую диффузионную архитектуру генерации аудио из текста на основе трансформера, которая использует латентное пространство 1D VAE и вдохновлённое FIT локальное/глобальное внимание для эффективной генерации аудио.
- Эксперименты показывают явные улучшения по сравнению с сопоставимыми базовыми моделями генерации аудио из текста, включая прирост по FAD, Inception Score и согласованности CLAP.
- Статья предоставляет необычно полный рецепт масштабирования для генерации фонового аудио, улучшая набор данных, конвейер описания и архитектуру модели совместно, а не рассматривая их как отдельные проблемы.
Ограничения и предостережения
- AutoCap дообучается на AudioCaps, чей словарь ограничен, поэтому очень детальные или необычные запросы всё ещё могут представлять трудность; статья представляет это как прямой путь к будущим улучшениям модели описания и набора данных.
- AutoReCap-XL проверяется главным образом через эксперименты по генерации аудио, что является сильным первым сценарием использования, оставляя при этом поиск аудио, понимание аудио и задачи аудио-видео в качестве многообещающих расширений.
- Конвейер сбора данных опирается на транскрипты, метаданные и эвристики фильтрации, но именно это делает его достаточно эффективным, чтобы масштабироваться далеко за пределы вручную описанных наборов данных фонового аудио.
- GenAu нацелен на фоновые звуки, а не на генерацию речи или музыки, что придаёт статье сфокусированный вклад, оставляя смежные аудиообласти естественными возможностями для адаптации.
- Крупномасштабное обучение и модель на 1,25 млрд параметров требуют значительных вычислений, но результаты убедительно доказывают, что эти вложения дают лучшее поведение при масштабировании для генерации фонового аудио.
Как интерпретировать этот результат
Эту статью лучше всего рассматривать как крупное системное продвижение в генерации фонового аудио: объединяя огромный переописанный набор данных, более сильную модель описания и масштабируемый трансформерный диффузионный генератор, она даёт области практичный рецепт повышения качества генерации аудио из текста за счёт масштабирования как данных, так и модели.