GViT: Representing Images as Gaussians for Visual Recognition
Краткое изложение пресс-релиза
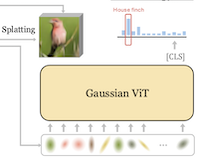
Исследователи из Rice University и UC Irvine создали новую систему классификации изображений, которая отказывается от традиционного подхода подачи нейронной сети сетки пикселей или прямоугольных патчей, заменяя этот вход компактным набором математических пятен, называемых 2D-гауссианами. Система под названием GViT работает за счёт обучения небольшой сети-энкодера описывать каждое изображение с помощью нескольких сотен гауссиан, где каждое пятно несёт информацию о своей позиции, размере, ориентации, цвете и непрозрачности. Изящная часть схемы обучения состоит в том, что модель классификации и энкодер гауссиан обучаются совместно в контуре обратной связи: градиенты от классификатора — по сути, сигналы о том, какие части изображения важны для определения его содержания — подаются обратно, чтобы направить гауссианы к областям, которые действительно полезны для распознавания, вместо того чтобы позволять им равномерно распределяться по неинформативному фону. Используя этот подход на стандартном бенчмарке ImageNet-1k, лучшая версия GViT достигла точности top-1 76,9% с архитектурой ViT-Base по сравнению с примерно 78,7% для традиционного ViT на основе патчей сопоставимого размера — разрыв менее двух процентных пунктов при использовании принципиально иного и гораздо более компактного входного представления. Работа важна не потому, что она сразу же превосходит существующие системы, а потому, что она демонстрирует, что промежуточные, интерпретируемые человеком геометрические примитивы могут поддерживать конкурентоспособное визуальное распознавание, и в качестве побочного эффекта обученные гауссианы склонны группироваться вокруг тех частей сцены, которые модель считает наиболее различающими, предлагая лёгкую форму объяснимости, которую модели на основе сетки пикселей естественным образом не обеспечивают.
аннотация
Мы представляем GVIT — фреймворк классификации, который отказывается от традиционных входных представлений в виде сетки пикселей или патчей в пользу компактного набора обучаемых 2D-гауссиан. Каждое изображение кодируется несколькими сотнями гауссиан, чьи позиции, масштабы, ориентации, цвета и непрозрачности оптимизируются совместно с ViT-классификатором, обучаемым поверх этих представлений. Мы повторно используем градиенты классификатора как конструктивное руководство, направляя гауссианы к областям, значимым для класса, в то время как дифференцируемый рендерер оптимизирует функцию потерь реконструкции изображения. Мы показываем, что входные представления в виде 2D-гауссиан в сочетании с нашим руководством GVIT, при использовании относительно стандартной архитектуры ViT, близко соответствуют производительности традиционного ViT на основе патчей, достигая точности top-1 76,9% на Imagenet-1k при использовании архитектуры ViT-B.
цитирование
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое GViT и какую проблему он решает? GViT — это фреймворк визуального распознавания, который заменяет фиксированные входы в виде сетки пикселей или патчей компактным набором обучаемых 2D-гауссовых примитивов, проверяя, могут ли геометрические представления среднего уровня поддерживать конкурентоспособную классификацию изображений.
- Как обучаются гауссианы? Деноизирующий энкодер гауссиан предсказывает центры, масштабы, ориентации, цвета и непрозрачности гауссиан, в то время как дифференцируемый рендерер оптимизирует реконструкцию изображения, а ViT-классификатор поставляет конструктивные градиенты, которые направляют гауссианы к областям, значимым для класса.
- Насколько хорошо GViT работает на ImageNet-1k? Управляемая модель GViT-B достигает точности top-1 76,9% на ImageNet-1k, что близко к 78,7%, заявленным для ViT-B/16 на основе патчей сопоставимого размера, при использовании существенно иного входного представления в виде гауссиан.
- Почему важно руководство градиентами классификатора? В статье сообщается, что руководство улучшает GViT-B с 73,6% до 76,9% на ImageNet-1k и аналогично улучшает меньшие модели, показывая, что учитывающее задачу размещение гауссиан является центральным для того, чтобы сделать представление полезным для распознавания.
- Обеспечивает ли GViT преимущества в интерпретируемости? Да, обученные ковариации гауссиан и карты внимания, различающие классы, склонны концентрироваться на областях изображения, релевантных классу, придавая представлению геометрическое визуальное объяснение, которое стандартные патч-токены естественным образом не раскрывают.
Основные вклады
- В статье представлено совместимое с ViT представление изображения, основанное на наборах 2D-гауссовых примитивов, а не на пикселях, патчах, сырых байтах или сжатых частотных коэффициентах.
- GViT предлагает кооперативную схему обучения, в которой функции потерь реконструкции сохраняют точность изображения, в то время как градиенты классификатора активно перемещают гауссианы к различающим визуальным признакам.
- Эксперименты на ImageNet-1k показывают, что входы в виде гауссиан могут достигать точности top-1 76,9% с бэкбоном ViT-B, превосходя несколько непатчевых входных альтернатив, перечисленных в статье, и приближаясь к 1,8 пункта от традиционного ViT-B/16 на основе патчей.
- Абляции на Mini-ImageNet-100 показывают, что деноизинг и руководство градиентами классификатора значимо улучшают размещение гауссиан, причём полная управляемая версия превосходит офлайн-подгонку гауссиан, обучаемые запросы и неуправляемый деноизинг.
- Анализ показывает, что масштаб гауссиан и сигналы внимания согласуются с областями, различающими классы, поддерживая утверждение о том, что GViT предлагает компактное представление для распознавания с естественной компонентой интерпретируемости.
Ограничения и предостережения
- ViT на основе патчей сегодня остаются наиболее прагматичным выбором для многих крупномасштабных развёртываний, но небольшой разрыв в точности GViT на ImageNet-1k убедительно показывает, что гауссовы примитивы уже являются жизнеспособной и удивительно конкурентоспособной альтернативной формой представления.
- Число гауссиан фиксируется до обучения, поэтому будущие версии могли бы выиграть от динамического порождения, отсечения или перераспределения; монотонный прирост, наблюдаемый по мере увеличения бюджета гауссиан, даёт полезные ориентиры для следующего шага проектирования.
- Дифференцируемый рендеринг добавляет накладные расходы на память и вычисления, особенно при высоких разрешениях или при более чем 512 гауссианах на обучении масштаба ImageNet; это инженерное узкое место вокруг в остальном многообещающего представления, а не слабость основной идеи.
- Эксперименты сосредоточены на классификации изображений и бенчмарках трансферной классификации, а не на задачах плотного предсказания, таких как детекция или сегментация; раскладки гауссиан, значимых для класса, наводят на мысль, что эти задачи являются естественными местами для дальнейшего исследования представления.
- Текущий подход по своему замыслу отбрасывает некоторые мелкие детали пикселей, что помогает сделать представление компактным и интерпретируемым, оставляя место для будущей работы по настройке баланса между точностью реконструкции и семантическим различением.
Как интерпретировать этот результат
Эту статью лучше всего рассматривать как сильный, подкреплённый доказательствами аргумент в пользу того, что визуальное распознавание не обязано быть привязано к сеткам пикселей или патчей: GViT удерживает производительность на ImageNet близко к стандартным ViT, вводя при этом интерпретируемое представление в виде гауссиан, которое открывает многообещающее направление для будущих визуальных бэкбонов.