Instance-level Image Retrieval using Reranking Transformers
Краткое изложение пресс-релиза
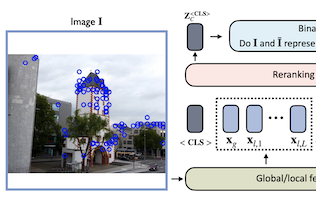
Исследователи из University of Virginia, eBay и Rice University разработали легковесную модель нейронной сети под названием Reranking Transformer, или RRT, которая повышает точность систем поиска изображений, пытающихся идентифицировать конкретные объекты или достопримечательности, а не широкие категории. Проблема, за которую взялась команда, — это двухэтапный процесс, распространённый в поиске изображений: первый проход использует компактный глобальный дескриптор изображения для составления короткого списка кандидатов-совпадений, а второй проход уточняет этот список с использованием более детальных локальных признаков — этап, традиционно решаемый геометрической верификацией, вычислительно дорогой техникой, которая пытается оценить, как одно изображение можно геометрически преобразовать, чтобы оно совпало с другим. Исследователи заменили этот второй этап небольшой моделью на основе трансформера, позаимствовав основанную на механизме внимания архитектуру, которая обусловила недавние достижения в обработке естественного языка, и обучили её напрямую предсказывать, показывают ли два изображения один и тот же объект или сцену. Имея всего около 2.2 миллиона параметров — примерно 9 процентов от размера стандартного бэкбона ResNet50 — и требуя лишь вдвое меньше локальных дескрипторов признаков, чем геометрическая верификация, RRT тем не менее превзошёл геометрическую верификацию и другие конкурирующие подходы на стандартных бенчмарках, включая наборы данных Revisited Oxford и Paris и Google Landmarks v2. Ключевое практическое преимущество в том, что переранжирование целого короткого списка из 100 изображений-кандидатов занимает лишь один прямой проход через сеть. Исследователи также показали, что, в отличие от геометрической верификации, RRT можно обучать совместно с лежащим в основе экстрактором признаков, позволяя оптимизировать оба компонента вместе и получая дальнейший прирост точности — возможность, которую они продемонстрировали на наборе данных Stanford Online Products.
аннотация
Поиск изображений на уровне экземпляров — это задача поиска в большой базе данных изображений, соответствующих объекту на изображении-запросе. Для решения этой задачи системы обычно опираются на этап поиска, использующий глобальные дескрипторы изображений, и последующий этап, выполняющий специфичные для домена уточнения или переранжирование за счёт таких операций, как геометрическая верификация на основе локальных признаков. В этой работе мы предлагаем Reranking Transformers (RRTs) как универсальную модель, объединяющую локальные и глобальные признаки для переранжирования соответствующих изображений в режиме обучения с учителем и тем самым заменяющую относительно дорогостоящий процесс геометрической верификации. RRTs легковесны и легко поддаются распараллеливанию, так что переранжирование набора лучших совпадающих результатов может выполняться за один прямой проход. Мы проводим обширные эксперименты на наборах данных Revisited Oxford и Paris, а также на наборе данных Google Landmarks v2, показывая, что RRTs превосходят прежние подходы к переранжированию, используя при этом гораздо меньше локальных дескрипторов. Более того, мы демонстрируем, что, в отличие от существующих подходов, RRTs могут оптимизироваться совместно с экстрактором признаков, что может приводить к представлениям признаков, адаптированным под целевые задачи, и к дальнейшему повышению точности. Код и обученные модели публично доступны по адресу https://github.com/uvavision/RerankingTransformer.
подробности
цитирование
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}