ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Краткое изложение пресс-релиза
Исследователи из Rice University, University of Illinois Urbana-Champaign и University of Virginia разработали метод под названием ProxyThinker, который позволяет большим моделям зрения и языка рассуждать более тщательно на этапе тестирования — без какого-либо дополнительного обучения. Проблема, которую они стремились решить, носит практический характер: чтобы научить большие модели искусственного интеллекта «замедляться» и пошагово прорабатывать сложные визуальные задачи, обычно требуется дорогостоящий reinforcement fine-tuning — процесс, который требует огромных вычислительных ресурсов и редко применялся к моделям крупнее семи миллиардов параметров. ProxyThinker полностью обходит эти затраты, запуская две небольшие вспомогательные модели рядом с большой моделью во время инференса — одну, уже дообученную тщательно рассуждать, и другую, которая не была дообучена, — и используя разницу между их выходными распределениями, чтобы подталкивать пословную генерацию большой модели к более обдуманному, самопроверяющемуся рассуждению. На практике это означает, что большая модель начинает проявлять такие формы поведения, как возврат к предыдущим шагам, самопроверка и многошаговая коррекция, которые она иначе редко производила бы. Протестировав подход на стандартных визуальных математических и междисциплинарных бенчмарках, команда обнаружила, что базовая модель с 32 миллиардами параметров, направляемая слабым экспертом-рассуждателем на 7 миллиардов параметров, может сравняться по производительности или слегка превзойти специализированную модель на 32 миллиарда параметров, полностью дообученную с помощью Reinforcement Learning. Команда также разработала параллелизованную реализацию на основе фреймворка инференса vLLM, которая работает примерно в 38 раз быстрее, чем более ранние методы направления на этапе декодирования, приближая фактическое время инференса к простому запуску одной большой модели. Эта работа важна, поскольку она предлагает вычислительно доступный путь к более сильному визуальному рассуждению в больших моделях в то время, когда затраты на обучение reinforcement fine-tuning масштаба передовых моделей остаются недостижимыми для большинства исследовательских групп.
аннотация
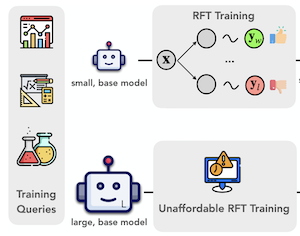
Недавние достижения в Reinforcement Learning с проверяемыми наградами расширили границы возможностей визуального рассуждения в больших моделях зрения и языка (LVLM). Однако обучение LVLM с помощью reinforcement fine-tuning (RFT) требует значительных вычислительных ресурсов, что создаёт серьёзную проблему при масштабировании размера модели. В этой работе мы предлагаем ProxyThinker — технику этапа инференса, которая позволяет большим моделям наследовать возможности визуального рассуждения от небольших, медленно размышляющих визуальных «рассуждателей» без какого-либо обучения. Вычитая выходные распределения базовых моделей из распределений RFT-рассуждателей, ProxyThinker изменяет динамику декодирования и успешно вызывает медленное рассуждение, проявляющееся в возникающих сложных формах поведения, таких как самопроверка и самокоррекция. ProxyThinker стабильно повышает производительность на сложных визуальных бенчмарках в пространственном, математическом и междисциплинарном рассуждении, позволяя необученным базовым моделям конкурировать по производительности с их полномасштабными RFT-аналогами. Более того, наша реализация эффективно координирует несколько языковых моделей с помощью техник параллелизма и достигает до 38 $\times$ более быстрого инференса по сравнению с предыдущими методами на этапе декодирования, прокладывая путь к практическому применению ProxyThinker. Код доступен по адресу https://github.com/MrZilinXiao/ProxyThinker.
цитирование
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое ProxyThinker и какую проблему он решает? ProxyThinker — это не требующий обучения метод этапа инференса, который переносит поведение медленного визуального рассуждения от небольших визуальных рассуждателей, дообученных с помощью reinforcement learning, к более крупным базовым моделям зрения и языка.
- Как ProxyThinker направляет большую модель? На каждом шаге декодирования он добавляет разницу логитов между небольшим RFT-экспертом-рассуждателем и его небольшим базовым «любительским» аналогом к логитам большой базовой модели, побуждая большую модель генерировать токены, связанные с самопроверкой и многошаговым рассуждением.
- Почему метод полезен по сравнению с полным reinforcement fine-tuning? Он позволяет избежать обновления параметров большой модели, что делает его практичной альтернативой, когда полномасштабный reinforcement fine-tuning моделей зрения и языка на 32B или 72B слишком дорог.
- Насколько ProxyThinker улучшает результаты на бенчмарках визуального рассуждения? На пяти математических и междисциплинарных бенчмарках ProxyThinker улучшает Qwen2.5-VL-32B в среднем относительно до 2,4 процента и Qwen2.5-VL-72B в среднем относительно до 2,7 процента в зависимости от небольшого эксперта-рассуждателя.
- Меняет ли ProxyThinker стиль рассуждения большой модели? Да, в статье сообщается о большем количестве возвратов к предыдущим шагам, проверок и явных форм мышления, что показывает, что метод способен вызывать паттерны медленного рассуждения, а не просто менять вероятности итоговых ответов.
Основные вклады
- В статье представлена простая формулировка на этапе декодирования для переноса визуального рассуждения, которая использует разницу логитов на уровне токенов между небольшим RFT-экспертом и небольшой «любительской» моделью в качестве направляющего сигнала для более крупной базовой модели.
- ProxyThinker показывает, что небольшие визуальные рассуждатели могут улучшать значительно более крупные модели без обучения, включая модели зрения и языка на 32B и 72B, оценённые на MathVista, MathVerse, MathVision, MMMU-Pro и R1-OneVisionBench.
- Метод позволяет базовой модели Qwen2.5-VL-32B, направляемой экспертом на 7B, сравняться или слегка превзойти полную RFT-модель на 32B в некоторых конфигурациях бенчмарков, включая результат на MathVision, выделенный в статье.
- Поведенческий анализ демонстрирует, что ProxyThinker способен сочетать способность большой модели планировать подцели со склонностью небольшого эксперта к самопроверке и возврату к предыдущим шагам.
- Реализация на основе vLLM эффективно координирует несколько моделей и обеспечивает ускорение в 38 раз по сравнению с более ранними реализациями направления на этапе декодирования в стиле HuggingFace, что делает подход гораздо более практичным.
Ограничения и предостережения
- ProxyThinker зависит от наличия доступа к полезному небольшому RFT-рассуждателю и соответствующей ему базовой «любительской» модели, поэтому будущие работы могли бы расширить рецепт на большее число семейств моделей и открытые пары эксперт-любитель.
- Метод запускает несколько моделей на этапе инференса, что добавляет системной сложности по сравнению с базовой моделью из одной модели; оптимизированная реализация на vLLM в статье существенно снижает эти накладные расходы и показывает, что подход может быть практичным.
- Прирост производительности варьируется в зависимости от бенчмарков и экспертов, причём некоторые конфигурации показывают меньшие улучшения, чем другие; эта вариативность полезным образом выявляет выбор эксперта и силу направления как важные параметры настройки для будущих систем рассуждения на этапе декодирования.
- Эксперименты сосредоточены на устоявшихся визуальных математических и междисциплинарных бенчмарках, оставляя интерактивные, долгосрочные и реальные сценарии развёртывания в качестве естественных следующих испытаний для той же идеи направления.
- ProxyThinker направляет поведение рассуждения на этапе декодирования, а не меняет базовые веса модели, что является преимуществом с точки зрения доступности и стоимости, при этом будущие работы могли бы изучить, как он дополняет методы на этапе обучения.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильный и практичный вклад в эффективное визуальное рассуждение: ProxyThinker показывает, что небольшие обученные рассуждатели способны раскрыть лучшее поведение медленного рассуждения у гораздо более крупных моделей на этапе тестирования, предлагая убедительную альтернативу или дополнение к дорогостоящему полномасштабному reinforcement fine-tuning.