Obj2Text: Generating Visually Descriptive Language from Object Layouts
Краткое изложение пресс-релиза
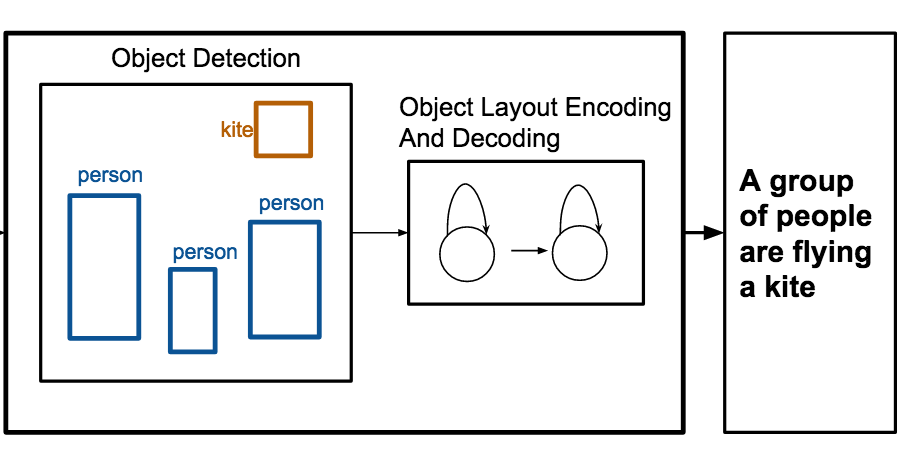
Исследователи из University of Virginia построили систему, которая может автоматически писать подписи, описывающие сцену, используя не более чем список объектов и их позиций на изображении, обходя необходимость в исходных пиксельных данных. Система под названием OBJ2TEXT работает, подавая метки объектов и координаты их ограничивающих рамок в одну нейронную сеть, которая кодирует компоновку как последовательность, а затем передавая это закодированное представление во вторую нейронную сеть, которая генерирует предложение слово за словом. Тестируя на стандартном наборе данных изображений MS-COCO, команда обнаружила, что расположение объектов и их количество оба значимо улучшали качество подписей — удаление любого из них вызывало измеримое падение качества — демонстрируя, что даже последовательное кодирование пространственной информации несёт реальную описательную ценность. Возможно, более практично то, что когда исследователи объединили OBJ2TEXT с детектором объектов под названием YOLO и обычной моделью подписывания на основе изображений, гибридная система превзошла базовую модель подписывания только по изображению, подняв её показатель CIDEr с 0.863 до 0.950 на бенчмарке MS-COCO; люди-оценщики также предпочитали подписи объединённой системы примерно в 65 процентах случаев, когда они все соглашались. Работа важна тем, что показывает: структурированная символическая информация о сцене — та, что производится детекторами объектов или используется в графическом дизайне и раскадровке — может дополнять или даже частично замещать пиксельные визуальные признаки в генерации языка, предлагая более чистый способ изучения того, что моделям подписывания изображений на самом деле нужно знать о сцене.
аннотация
Генерация подписей к изображениям — это задача, которая в последнее время получила значительное внимание. В этой работе мы фокусируемся на генерации подписей для абстрактных сцен, или компоновок объектов, где единственная предоставленная информация — это набор объектов и их расположений. Мы предлагаем OBJ2TEXT — модель sequence-to-sequence, которая кодирует набор объектов и их расположений как входную последовательность с помощью сети LSTM и декодирует это представление с помощью языковой модели LSTM. Мы показываем, что наша модель, несмотря на кодирование компоновок объектов как последовательности, способна представлять пространственные отношения между объектами и генерировать описания, которые глобально связны и семантически релевантны. Мы тестируем наш подход в задаче подписывания компоновки объектов, используя в качестве входных данных только аннотации объектов. Дополнительно мы показываем, что наша модель в сочетании с детектором объектов современного уровня улучшает модель подписывания изображений с 0.863 до 0.950 (по метрике CIDEr) на тестовом бенчмарке стандартной задачи MS-COCO Captioning.
подробности
цитирование
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}