Evolving Image Compositions for Feature Representation Learning
Tóm tắt thông cáo báo chí
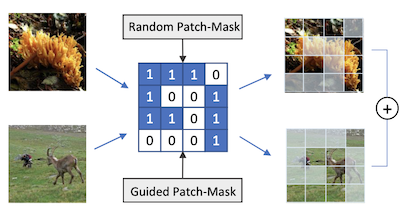
Các nhà nghiên cứu tại University of Virginia và Rice University đã phát triển một kỹ thuật tăng cường dữ liệu có tên PatchMix giúp các mạng nơ-ron nhận dạng ảnh học tốt hơn bằng cách huấn luyện trên các ảnh lai được dựng nhân tạo. Vấn đề cốt lõi là các mô hình Deep Learning cho nhận dạng thị giác có xu hướng quá khớp với dữ liệu huấn luyện của chúng, và mặc dù các phương pháp hiện có như Mixup và CutMix đã trộn các cặp ảnh lại với nhau để chống lại điều này, chúng bị hạn chế về mức độ linh hoạt khi kết hợp các ảnh đó. PatchMix giải quyết điều này bằng cách cắt hai ảnh thành một lưới các mảng có kích thước bằng nhau và hoán đổi các mảng giữa chúng theo một mặt nạ nhị phân, rồi gán cho ảnh tổng hợp thu được một nhãn pha trộn tỷ lệ thuận với số mảng đến từ mỗi nguồn. Nhóm cũng đã thêm một hàm mất mát phụ huấn luyện mạng nhận diện chính xác mỗi mảng riêng lẻ thuộc lớp nào, chứ không chỉ ảnh như một tổng thể, điều này buộc mô hình xây dựng các biểu diễn nhận biết cục bộ hơn. Đi xa hơn, các nhà nghiên cứu đã sử dụng một thuật toán tìm kiếm di truyền để tự động khám phá những cặp danh mục ảnh nào hữu ích nhất để trộn với nhau, và những mẫu lưới nào tạo ra các ví dụ huấn luyện thách thức nhất — và do đó giàu thông tin nhất — tất cả mà không cần huấn luyện lại mô hình từ đầu cho mỗi cấu hình ứng viên. Khi được kiểm tra trên các benchmark tiêu chuẩn, một mô hình ResNet-50 được huấn luyện với PatchMix đã vượt trội các mô hình cơ sở trên CIFAR-10, CIFAR-100, Tiny ImageNet, và ImageNet, và thể hiện hiệu năng Transfer Learning mạnh hơn trên các tác vụ bao gồm phát hiện đối tượng, nhận dạng cảnh, và tạo chú thích ảnh, gợi ý rằng phương pháp tạo ra các đặc trưng thị giác đa năng hơn so với các cách tiếp cận cạnh tranh.
tóm tắt
Các mạng nơ-ron tích chập cho nhận dạng thị giác đòi hỏi lượng lớn mẫu huấn luyện và thường hưởng lợi từ tăng cường dữ liệu. Bài báo này đề xuất PatchMix, một phương pháp tăng cường dữ liệu tạo ra các mẫu mới bằng cách ghép các mảng từ các cặp ảnh theo một mẫu dạng lưới. Các mẫu mới này được gán các điểm số nhãn tỷ lệ thuận với số mảng được mượn từ mỗi ảnh. Sau đó chúng tôi thêm một tập các mất mát bổ sung ở cấp độ mảng để điều chuẩn và để khuyến khích các biểu diễn tốt ở cả cấp độ mảng và cấp độ ảnh. Một mô hình ResNet-50 được huấn luyện trên ImageNet bằng PatchMix thể hiện các khả năng Transfer Learning vượt trội trên một loạt rộng các benchmark. Mặc dù PatchMix có thể dựa vào các cặp ghép ngẫu nhiên và các mẫu dạng lưới ngẫu nhiên để trộn, chúng tôi khám phá tìm kiếm tiến hóa như một chiến lược dẫn dắt để cùng lúc khám phá các mẫu dạng lưới và các cặp ghép ảnh tối ưu. Cho mục đích này, chúng tôi hình thành một hàm thích nghi bỏ qua được nhu cầu huấn luyện lại một mô hình để đánh giá mỗi lựa chọn khả dĩ. Theo cách này, PatchMix vượt trội một mô hình cơ sở trên CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), và ImageNet (+1.16).
chi tiết
trích dẫn
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}