CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
tóm tắt
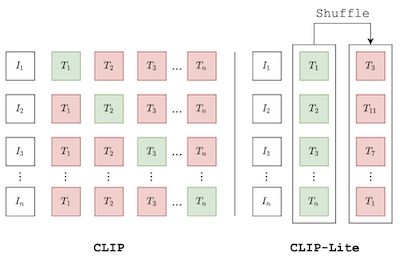
Chúng tôi đề xuất CLIP-Lite, một phương pháp hiệu quả về thông tin cho học biểu diễn thị giác bằng cách căn chỉnh đặc trưng với các chú thích văn bản. So với mô hình CLIP được đề xuất trước đây, CLIP-Lite chỉ yêu cầu một cặp mẫu ảnh-văn bản âm cho mỗi mẫu ảnh-văn bản dương trong quá trình tối ưu hóa mục tiêu Contrastive Learning của nó. Chúng tôi đạt được điều này bằng cách tận dụng một cận dưới hiệu quả về thông tin để cực đại hóa thông tin tương hỗ giữa hai phương thức đầu vào. Điều này cho phép CLIP-Lite được huấn luyện với lượng dữ liệu và kích thước batch giảm đi đáng kể trong khi đạt được hiệu năng tốt hơn CLIP ở cùng quy mô. Chúng tôi đánh giá CLIP-Lite bằng cách tiền huấn luyện trên bộ dữ liệu COCO-Captions và kiểm tra Transfer Learning sang các bộ dữ liệu khác. CLIP-Lite đạt được mức tăng tuyệt đối +14,0% mAP về hiệu năng trên phân loại Pascal VOC, và mức tăng độ chính xác top-1 +22,1% trên ImageNet, trong khi tương đương hoặc vượt trội hơn các mô hình được giám sát bằng văn bản khác phức tạp hơn. CLIP-Lite cũng vượt trội hơn CLIP về truy hồi ảnh và văn bản, phân loại Zero-Shot và định vị thị giác. Cuối cùng, chúng tôi cho thấy rằng CLIP-Lite có thể tận dụng ngữ nghĩa của ngôn ngữ để khuyến khích các biểu diễn thị giác không thiên kiến có thể được dùng trong các nhiệm vụ hạ nguồn. Cài đặt: https://github.com/4m4n5/CLIP-Lite
trích dẫn
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}