ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Tóm tắt thông cáo báo chí
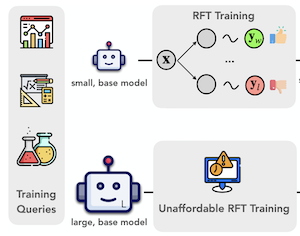
Các nhà nghiên cứu tại Rice University, University of Illinois Urbana-Champaign và University of Virginia đã phát triển một phương pháp tên là ProxyThinker cho phép các mô hình thị giác-ngôn ngữ lớn suy luận cẩn thận hơn tại thời điểm kiểm tra — mà không cần bất kỳ huấn luyện bổ sung nào. Vấn đề họ đặt ra để giải quyết mang tính thực tiễn: dạy cho các mô hình AI lớn "chậm lại" và xử lý từng bước các bài toán thị giác phức tạp thường đòi hỏi reinforcement fine-tuning tốn kém, một quá trình yêu cầu nguồn lực tính toán khổng lồ và hiếm khi được áp dụng cho các mô hình lớn hơn bảy tỷ tham số. ProxyThinker hoàn toàn né tránh chi phí đó bằng cách chạy hai mô hình đồng hành nhỏ song song với mô hình lớn trong quá trình suy luận — một mô hình đã được tinh chỉnh để suy luận cẩn thận, và một mô hình thì chưa — và sử dụng sự khác biệt giữa phân phối đầu ra của chúng để hướng quá trình sinh từng token của mô hình lớn về phía lối suy luận có chủ đích, tự kiểm tra hơn. Trên thực tế, điều này có nghĩa là mô hình lớn bắt đầu thể hiện các hành vi như quay lui, tự kiểm chứng và sửa lỗi nhiều bước mà nếu không thì nó hiếm khi tạo ra. Khi thử nghiệm phương pháp này trên các benchmark toán học thị giác và đa lĩnh vực tiêu chuẩn, nhóm nghiên cứu nhận thấy rằng một mô hình nền 32 tỷ tham số được dẫn dắt bởi một chuyên gia suy luận yếu 7 tỷ tham số có thể sánh ngang hoặc vượt nhẹ hiệu năng của một mô hình chuyên dụng 32 tỷ tham số đã được tinh chỉnh đầy đủ bằng Reinforcement Learning. Nhóm cũng thiết kế một cách triển khai song song hóa trên nền tảng framework suy luận vLLM, chạy nhanh hơn khoảng 38 lần so với các phương pháp dẫn hướng tại thời điểm giải mã trước đó, đưa thời gian suy luận thực tế gần với việc chỉ chạy một mô hình lớn đơn lẻ. Công trình này quan trọng vì nó mở ra một con đường khả thi về mặt tính toán hướng tới suy luận thị giác mạnh hơn trong các mô hình lớn, vào thời điểm mà chi phí huấn luyện reinforcement fine-tuning quy mô tiên phong vẫn nằm ngoài tầm với của phần lớn các nhóm nghiên cứu.
tóm tắt
Những tiến bộ gần đây trong reinforcement learning với phần thưởng có thể kiểm chứng đã mở rộng giới hạn năng lực suy luận thị giác trong các mô hình thị giác-ngôn ngữ lớn (LVLM). Tuy nhiên, việc huấn luyện LVLM bằng reinforcement fine-tuning (RFT) tốn kém về mặt tính toán, đặt ra một thách thức lớn cho việc mở rộng quy mô mô hình. Trong công trình này, chúng tôi đề xuất ProxyThinker, một kỹ thuật tại thời điểm suy luận cho phép các mô hình lớn kế thừa năng lực suy luận thị giác từ các bộ suy luận thị giác nhỏ, suy nghĩ chậm mà không cần bất kỳ huấn luyện nào. Bằng cách trừ phân phối đầu ra của các mô hình nền khỏi phân phối của các bộ suy luận RFT, ProxyThinker điều chỉnh động lực giải mã và khơi gợi thành công lối suy luận suy nghĩ chậm được thể hiện qua các hành vi tinh vi đã xuất hiện như tự kiểm chứng và tự sửa lỗi. ProxyThinker liên tục nâng cao hiệu năng trên các benchmark thị giác đầy thách thức về suy luận không gian, toán học và đa lĩnh vực, cho phép các mô hình nền chưa được tinh chỉnh cạnh tranh với hiệu năng của các đối tác RFT quy mô đầy đủ của chúng. Hơn nữa, cách triển khai của chúng tôi điều phối hiệu quả nhiều mô hình ngôn ngữ bằng các kỹ thuật song song hóa và đạt tốc độ suy luận nhanh hơn tới 38 $\times$ so với các phương pháp tại thời điểm giải mã trước đây, mở đường cho việc triển khai thực tế của ProxyThinker. Mã nguồn có tại https://github.com/MrZilinXiao/ProxyThinker.
trích dẫn
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- ProxyThinker là gì và nó giải quyết vấn đề nào? ProxyThinker là một phương pháp tại thời điểm suy luận không cần huấn luyện, chuyển giao hành vi suy luận thị giác suy nghĩ chậm từ các bộ suy luận thị giác nhỏ được reinforcement-fine-tuned sang các mô hình thị giác-ngôn ngữ nền lớn hơn.
- ProxyThinker dẫn hướng một mô hình lớn như thế nào? Tại mỗi bước giải mã, nó cộng phần chênh lệch logit giữa một chuyên gia suy luận RFT nhỏ và đối tác nghiệp dư nền nhỏ của nó vào logit của mô hình nền lớn, khuyến khích mô hình lớn sinh ra các token liên quan đến việc tự kiểm tra và suy luận nhiều bước.
- Tại sao phương pháp này hữu ích so với reinforcement fine-tuning đầy đủ? Nó tránh việc cập nhật tham số của mô hình lớn, điều này khiến nó trở thành một lựa chọn thực tế khi reinforcement fine-tuning quy mô đầy đủ của các mô hình thị giác-ngôn ngữ 32B hoặc 72B quá tốn kém.
- ProxyThinker cải thiện các benchmark suy luận thị giác bao nhiêu? Trên năm benchmark toán học và đa lĩnh vực, ProxyThinker cải thiện Qwen2.5-VL-32B với mức cải thiện tương đối trung bình lên tới 2,4 phần trăm và Qwen2.5-VL-72B với mức cải thiện tương đối trung bình lên tới 2,7 phần trăm tùy thuộc vào chuyên gia suy luận nhỏ.
- ProxyThinker có thay đổi phong cách suy luận của mô hình lớn không? Có, bài báo ghi nhận nhiều hành vi quay lui, kiểm chứng và suy nghĩ tường minh hơn, cho thấy phương pháp có thể khơi gợi các mẫu suy nghĩ chậm thay vì chỉ đơn thuần thay đổi xác suất của câu trả lời cuối cùng.
Đóng góp chính
- Bài báo giới thiệu một công thức tại thời điểm giải mã đơn giản cho việc chuyển giao suy luận thị giác, sử dụng phần chênh lệch logit ở cấp độ token giữa một chuyên gia RFT nhỏ và một mô hình nghiệp dư nhỏ làm hướng dẫn cho một mô hình nền lớn hơn.
- ProxyThinker cho thấy rằng các bộ suy luận thị giác nhỏ có thể cải thiện đáng kể các mô hình lớn hơn nhiều mà không cần huấn luyện, bao gồm các mô hình thị giác-ngôn ngữ 32B và 72B được đánh giá trên MathVista, MathVerse, MathVision, MMMU-Pro và R1-OneVisionBench.
- Phương pháp này cho phép một mô hình nền Qwen2.5-VL-32B được dẫn dắt bởi một chuyên gia 7B sánh ngang hoặc vượt nhẹ một mô hình RFT 32B đầy đủ trong một số cấu hình benchmark, bao gồm kết quả MathVision được nhấn mạnh trong bài báo.
- Phân tích hành vi chứng minh rằng ProxyThinker có thể kết hợp khả năng lập kế hoạch mục tiêu con của mô hình lớn với xu hướng tự kiểm chứng và quay lui của chuyên gia nhỏ.
- Cách triển khai dựa trên vLLM điều phối nhiều mô hình một cách hiệu quả và ghi nhận tốc độ tăng 38 lần so với các cách triển khai dẫn hướng tại thời điểm giải mã kiểu HuggingFace trước đây, khiến phương pháp trở nên thực tế hơn nhiều.
Hạn chế và lưu ý
- ProxyThinker phụ thuộc vào việc có quyền truy cập một bộ suy luận thị giác RFT nhỏ hữu ích và mô hình nghiệp dư nền tương ứng của nó, vì vậy công trình tương lai có thể mở rộng công thức này sang nhiều họ mô hình hơn và các cặp chuyên gia-nghiệp dư mở.
- Phương pháp này chạy nhiều mô hình tại thời điểm suy luận, điều này làm tăng độ phức tạp của hệ thống so với một baseline mô hình đơn lẻ; cách triển khai vLLM tối ưu hóa của bài báo giảm đáng kể chi phí phụ trội này và cho thấy phương pháp có thể khả thi.
- Mức cải thiện hiệu năng dao động giữa các benchmark và các chuyên gia, với một số cấu hình cho thấy cải thiện nhỏ hơn so với các cấu hình khác; sự biến thiên này một cách hữu ích xác định việc lựa chọn chuyên gia và cường độ dẫn hướng là những núm điều chỉnh quan trọng cho các hệ thống suy luận tại thời điểm giải mã trong tương lai.
- Các thí nghiệm tập trung vào các benchmark toán học thị giác và đa lĩnh vực đã được thiết lập, để lại các kịch bản tương tác, dài hạn và triển khai thực tế như những phép kiểm tra tiếp theo tự nhiên cho cùng ý tưởng dẫn hướng này.
- ProxyThinker dẫn hướng hành vi suy luận tại thời điểm giải mã thay vì thay đổi trọng số nền tảng của mô hình, đây là một ưu điểm về khả năng tiếp cận và chi phí, trong khi công trình tương lai có thể nghiên cứu cách nó bổ trợ cho các phương pháp tại thời điểm huấn luyện.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một đóng góp mạnh mẽ và thực tiễn cho suy luận thị giác hiệu quả: ProxyThinker cho thấy rằng các bộ suy luận nhỏ đã được huấn luyện có thể mở khóa hành vi suy nghĩ chậm tốt hơn trong các mô hình lớn hơn nhiều tại thời điểm kiểm tra, mang lại một lựa chọn thay thế hoặc bổ trợ hấp dẫn cho reinforcement fine-tuning quy mô đầy đủ tốn kém.