Commonly Uncommon: Semantic Sparsity in Situation Recognition
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu tại University of Washington và Allen Institute for Artificial Intelligence đã giải quyết một vấn đề dai dẳng trong thị giác máy tính: khi các hệ thống AI cố gắng mô tả những gì đang diễn ra trong một bức ảnh một cách chi tiết và có cấu trúc — không chỉ xác định một hoạt động như "mang vác" mà còn ai đang mang, họ đang mang gì, và ở đâu — chúng có xu hướng sụp đổ bất cứ khi nào khung cảnh liên quan đến một tổ hợp đối tượng và vai trò bất thường. Nhóm nhận thấy rằng trong bộ dữ liệu benchmark imSitu, khoảng 35 phần trăm các dự đoán cần thiết liên quan đến các cặp đối tượng-vai trò được thấy ít hơn mười lần trong quá trình huấn luyện, và các mô hình hiện có mất đi độ chính xác đáng kể đúng trong những trường hợp đó. Để giải quyết điều này, các nhà nghiên cứu đã phát triển hai kỹ thuật bổ trợ cho nhau. Thứ nhất, họ thiết kế một mô hình toán học mới gọi là tiềm năng tensor có tính tổ hợp (compositional tensor potential), được nhúng bên trong khung Conditional Random Field, học các biểu diễn được chia sẻ của các danh từ qua các vai trò khác nhau — để rằng kiến thức về việc một "em bé" trông như thế nào, chẳng hạn, có thể thông tin cho các dự đoán bất kể em bé xuất hiện như là thứ được mang đi hay là người đang mang. Thứ hai, họ xây dựng một quy trình tăng cường dữ liệu ngữ nghĩa chuyển đổi các tình huống huấn luyện đã được chú thích thành các cụm từ văn bản ngắn, sử dụng những cụm từ đó để truy hồi khoảng năm triệu ảnh từ tìm kiếm ảnh của Google, và tích hợp các kết quả nhiễu thông qua huấn luyện theo khả năng cận biên (marginal likelihood) và tự-huấn luyện lặp đi lặp lại. Việc kết hợp cả hai phương pháp đã cải thiện độ chính xác động từ top-5 khoảng 6 phần trăm và độ chính xác danh từ-vai trò gần 10 phần trăm so với mức tốt nhất hiện nay trước đó, với các lợi ích tương đối còn lớn hơn nữa trên các trường hợp hiếm gặp mà công trình nhắm tới một cách cụ thể. Các phát hiện này có ý nghĩa quan trọng vì sự thưa thớt ngữ nghĩa — quá nhiều tổ hợp đầu ra khả dĩ, quá ít mẫu của hầu hết chúng — là một trở ngại phổ biến trong các nhiệm vụ hiểu thị giác có cấu trúc, và công trình này mang lại một chiến lược cụ thể, có thể mở rộng quy mô để làm cho các hệ thống AI đáng tin cậy hơn khi gặp phải những tình huống không phổ biến mà trên thực tế lại khá phổ biến trong thế giới thực.
tóm tắt
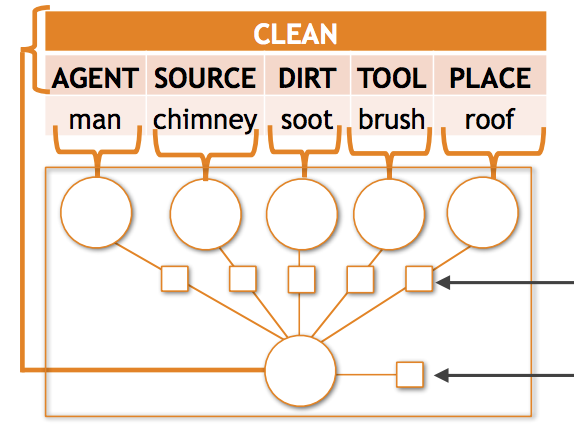
Sự thưa thớt ngữ nghĩa là một thách thức phổ biến trong các bài toán phân loại thị giác có cấu trúc; khi không gian đầu ra phức tạp, phần lớn các dự đoán khả dĩ hiếm khi, nếu có bao giờ, được thấy trong tập huấn luyện. Bài báo này nghiên cứu sự thưa thớt ngữ nghĩa trong nhận diện tình huống (situation recognition), nhiệm vụ tạo ra các bản tóm tắt có cấu trúc về những gì đang diễn ra trong ảnh, bao gồm các hoạt động, đối tượng và các vai trò mà các đối tượng đóng trong hoạt động đó. Đối với bài toán này, qua thực nghiệm chúng tôi nhận thấy rằng hầu hết các tổ hợp đối tượng-vai trò đều hiếm gặp, và các mô hình tốt nhất hiện nay có hiệu năng kém đi đáng kể trong chế độ dữ liệu thưa thớt này. Chúng tôi tránh được nhiều lỗi như vậy bằng cách (1) giới thiệu một hàm tổ hợp tensor mới mẻ học cách chia sẻ các mẫu giữa các tổ hợp vai trò-danh từ và (2) tăng cường về mặt ngữ nghĩa cho dữ liệu huấn luyện của chúng tôi bằng các mẫu được tự động thu thập của các đầu ra hiếm gặp bằng dữ liệu web. Khi được tích hợp vào trong một mô hình dự đoán có cấu trúc dựa trên CRF hoàn chỉnh, phương pháp dựa trên tensor vượt trội hơn mức tốt nhất hiện nay với mức cải thiện tương đối lần lượt là 2,11% và 4,40% về độ chính xác động từ và danh từ-vai trò top-5. Việc thêm 5 triệu ảnh bằng các kỹ thuật tăng cường ngữ nghĩa của chúng tôi mang lại các cải thiện tương đối hơn nữa là 6,23% và 9,57% về độ chính xác động từ và danh từ-vai trò top-5.
trích dẫn
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}