Obj2Text: Generating Visually Descriptive Language from Object Layouts
Tóm tắt thông cáo báo chí
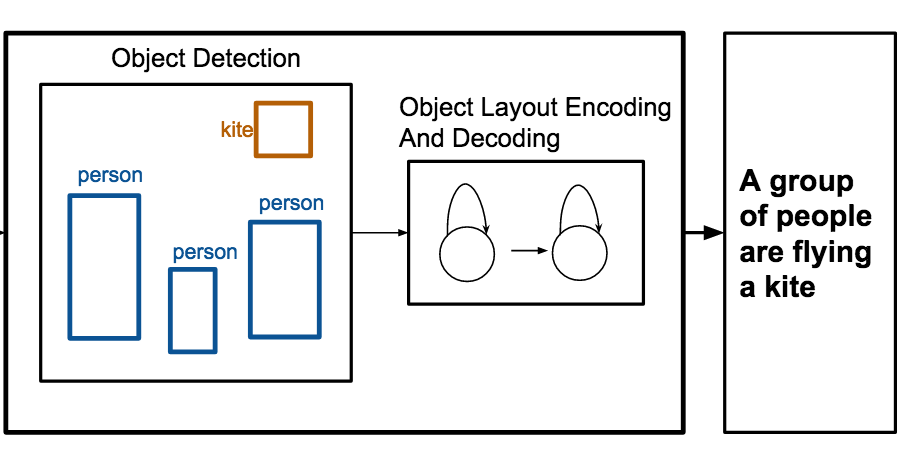
Các nhà nghiên cứu tại University of Virginia đã xây dựng một hệ thống có thể tự động viết các chú thích mô tả một cảnh chỉ bằng một danh sách các đối tượng và vị trí của chúng trong một bức ảnh, bỏ qua nhu cầu về dữ liệu pixel thô. Hệ thống, gọi là OBJ2TEXT, hoạt động bằng cách đưa các nhãn đối tượng và tọa độ hộp bao (bounding box) của chúng vào một mạng nơ-ron mã hóa bố cục thành một chuỗi, rồi chuyển biểu diễn đã mã hóa đó sang một mạng nơ-ron thứ hai sinh ra một câu theo từng từ. Khi thử nghiệm trên bộ dữ liệu ảnh MS-COCO tiêu chuẩn, nhóm nhận thấy rằng cả vị trí đối tượng và số lượng đối tượng đều cải thiện chất lượng chú thích một cách có ý nghĩa — loại bỏ bất kỳ yếu tố nào trong hai yếu tố này đều gây ra sự sụt giảm hiệu năng đo lường được — chứng minh rằng ngay cả một cách mã hóa tuần tự thông tin không gian cũng mang giá trị mô tả thực sự. Có lẽ thực tế hơn, khi các nhà nghiên cứu kết hợp OBJ2TEXT với một bộ phát hiện đối tượng tên là YOLO và một mô hình chú thích dựa trên ảnh thông thường, hệ thống lai đã vượt trội hơn baseline chú thích chỉ-dùng-ảnh, đẩy điểm CIDEr của nó từ 0,863 lên 0,950 trên benchmark MS-COCO; những người đánh giá là con người cũng ưa chuộng các chú thích của hệ thống kết hợp khoảng 65 phần trăm số lần khi tất cả họ đồng ý. Công trình này quan trọng vì nó cho thấy rằng thông tin có cấu trúc, mang tính biểu tượng về một cảnh — loại được tạo ra bởi các bộ phát hiện đối tượng hoặc được sử dụng trong thiết kế đồ họa và làm storyboard — có thể bổ trợ hoặc thậm chí thay thế một phần các đặc trưng thị giác ở cấp độ pixel trong việc sinh ngôn ngữ, mang lại một cách sạch sẽ hơn để nghiên cứu xem các mô hình chú thích ảnh thực sự cần biết gì về một cảnh.
tóm tắt
Sinh chú thích cho ảnh là một tác vụ gần đây đã nhận được sự chú ý đáng kể. Trong công trình này, chúng tôi tập trung vào việc sinh chú thích cho các cảnh trừu tượng, hay các bố cục đối tượng (object layout), nơi thông tin duy nhất được cung cấp là một tập các đối tượng và vị trí của chúng. Chúng tôi đề xuất OBJ2TEXT, một mô hình sequence-to-sequence mã hóa một tập các đối tượng và vị trí của chúng thành một chuỗi đầu vào bằng cách sử dụng một mạng LSTM, và giải mã biểu diễn này bằng một mô hình ngôn ngữ LSTM. Chúng tôi cho thấy rằng mô hình của chúng tôi, dù mã hóa các bố cục đối tượng dưới dạng một chuỗi, có thể biểu diễn các quan hệ không gian giữa các đối tượng, và sinh ra các mô tả mạch lạc về tổng thể và phù hợp về mặt ngữ nghĩa. Chúng tôi kiểm tra cách tiếp cận của mình trong một tác vụ chú thích bố cục đối tượng bằng cách chỉ sử dụng các chú thích đối tượng làm đầu vào. Chúng tôi cũng cho thấy thêm rằng mô hình của chúng tôi, khi kết hợp với một bộ phát hiện đối tượng tốt nhất hiện nay, cải thiện một mô hình chú thích ảnh từ 0,863 lên 0,950 (điểm CIDEr) trong benchmark kiểm tra của tác vụ MS-COCO Captioning tiêu chuẩn.
chi tiết
trích dẫn
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}