One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
新闻稿摘要
莱斯大学和 Snap Inc. 的研究人员开发了一种名为 ELIT(Elastic Latent Interface Transformer 的缩写)的技术,它赋予图像和视频生成模型一种能力:在运行时即时地在计算速度与输出质量之间进行权衡——而无需为每一个所需的工作点重新训练模型。他们所应对的核心问题是:标准的扩散 Transformer 模型不论某一图像块包含的是精细细节还是空白天空,都对每一块消耗相同的计算量,而且其计算成本被固定地绑定在图像分辨率上。为解决这一问题,团队在模型的早期与晚期处理阶段之间插入了一小组可学习的“潜在 token”,并用两个被他们称为 Read 与 Write 的轻量级交叉注意力层将其连接起来。在训练中,模型会随机丢弃其中的一些潜在 token,这迫使它把最重要的信息打包进它最常保留的那些 token 中,从而产生一种天然有序的表示。在推理时,用户只需选择使用多少个潜在 token,即可直接调高或调低计算量。在包括 DiT、U-ViT、HDiT 以及 200 亿参数的 Qwen-Image 模型在内的多种流行架构上进行测试,ELIT 都持续改善了图像质量指标——在 512 像素的 ImageNet 基准上将 FID 分数降低多达 53%——同时还让用户能够以仅有适度的质量损失将计算量削减约 35% 到 65%。该方法还借助同一模型的低 token 版本作为内置的“弱”参考,解锁了一种成本更低的无分类器引导(classifier-free guidance),使引导成本降低约三分之一。
摘要
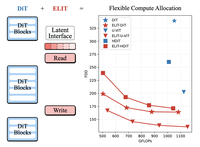
扩散 Transformer(DiTs)能够实现很高的生成质量,但会把 FLOPs 锁定在图像分辨率上,从而限制了在原理上对延迟与质量进行权衡的能力,并且会在所有输入空间 token 上均匀分配计算,把资源浪费在不重要的区域上。我们提出了弹性潜在接口 Transformer(Elastic Latent Interface Transformer,ELIT),这是一种即插即用、与 DiT 兼容的机制,可将输入图像尺寸与计算量解耦。我们的方法插入了一个潜在接口(latent interface),即一个可学习的、长度可变的 token 序列,标准 Transformer 模块可以在其上运行。轻量级的 Read 与 Write 交叉注意力层在空间 token 与潜在 token 之间传递信息,并对重要的输入区域进行优先处理。通过在训练中随机丢弃尾部潜在 token,ELIT 学会生成按重要性排序的表示,其中较早的潜在 token 捕捉全局结构,较晚的则包含用于细化细节的信息。在推理时,可动态调整潜在 token 的数量以匹配计算约束。ELIT 刻意保持极简,仅增加两个交叉注意力层,而保持修正流(rectified flow)目标和 DiT 主干不变。在多个数据集和架构(DiT、U-ViT、HDiT、MM-DiT)上,ELIT 都带来了一致的提升。在 ImageNet-1K 512px 上,ELIT 在 FID 和 FDD 指标上分别带来 $35.3\%$ 和 $39.6\%$ 的平均提升。项目主页:https://snap-research.github.io/elit/
详情
引用
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 ELIT,它解决了什么问题?ELIT 是一种面向扩散 Transformer 的即插即用潜在接口机制,它将计算量与图像分辨率解耦,使单个生成模型能够在多种质量与延迟预算下运行。
- ELIT 如何改造扩散 Transformer?它在一个简短的空间头部与尾部之间插入一组长度可变的潜在 token,并使用轻量级的 Read 与 Write 交叉注意力层在图像 token 与潜在接口之间传递信息。
- ELIT 如何提供灵活的推理预算?在训练中,尾部潜在 token 会被随机丢弃,从而使较早的 token 学到最重要的信息;在推理时,用户选择保留多少个潜在 token 来控制 FLOPs。
- ELIT 报告了哪些实证收益?在 ImageNet-1K 512px 上,ELIT 在 DiT、U-ViT 和 HDiT 主干上都显著改善了 FID 和 FDD,其中本文报告的 DiT 设置下 FID 提升高达 53%。
- ELIT 能否扩展到大型生成模型?可以,本文将 ELIT 应用于 Qwen-Image(一个 20B 的 MM-DiT 模型),展示了平滑的计算-质量权衡,在保持强劲 DPG-Bench 分数的同时实现了约 2.7 倍的加速。
主要贡献
- 本文提出了一个极简的 Read/Write 潜在接口,它保持修正流(rectified-flow)目标和主 DiT 主干不变,使 ELIT 易于嫁接到现有的扩散 Transformer 系列上。
- ELIT 通过使用 Read 层将信息丰富的空间区域拉入潜在接口,而不是在简单或填充区域上耗费相同的计算量,从而展示了自适应计算能力。
- 多预算训练策略创建了一个按重要性排序的潜在序列,使单组权重无需重新训练即可支持多种推理预算。
- 实验表明,ELIT 在 DiT、U-ViT 和 HDiT 上都带来了一致的图像生成提升,在 Kinetics-700 上取得了良好的视频生成结果,并与诸如 TeaCache 之类的免训练加速方法兼容。
- ELIT 通过使用同一模型的较低预算版本作为弱参考,实现了低成本的引导与自引导(autoguidance),在降低引导成本的同时提升了样本质量。
局限与注意事项
- ELIT 增加了 Read 与 Write 层以及潜在 token 调度,因此它是一项小幅的架构改动,而非纯粹的免训练加速方法;其即插即用的设计和在广泛主干上的结果使这一额外复杂度得到了充分的合理化。
- Qwen-Image 实验是利用现成的真实与合成数据对一个大型现有模型进行微调,而非复现原始模型完整的专有训练流程,但它仍然为 ELIT 可扩展到 20B 参数的 MM-DiT 系统提供了有价值的证据。
- 最低预算的 Qwen-Image 设置以一些基准质量换取速度,这对于弹性模型来说是预期之内的,而且也很有用,因为用户可以选择适合其延迟与质量需求的预算。
- 大多数详细的消融实验是在类条件 ImageNet 和 Kinetics 设置上进行的,这使得文本到图像的部署细节以及面向用户的质量偏好成为自然的未来评估方向。
- 该方法改善的是类 DiT 生成器内部的计算分配,而非取代所有其他效率技术,其与 TeaCache 和引导策略的兼容性表明,它可以与互补的加速器富有成效地结合使用。
如何理解这一结果
这篇论文最好被理解为一项面向扩散 Transformer 的强有力的系统与建模贡献:ELIT 让单个模型获得对计算预算的实用控制能力,在多个主干上提升了生成质量,并将这一思路扩展到大型现代图像生成器,同时保持核心架构改动的紧凑。