ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
新闻稿摘要
莱斯大学和 Google DeepMind 的研究人员开发了一种名为 ViC-MAE 的自监督视觉学习系统,它训练单个 AI 模型在无需标注数据的情况下同时理解静止图像和视频。他们要解决的核心挑战是,现有模型往往擅长其中一种模态而非两者兼顾——尤其是在视频上训练的模型,在被要求在图像任务上表现良好时历来举步维艰。他们的方法结合了两种现有技术:掩码自编码器(训练模型重建随机隐藏的图像图块)和对比学习(训练模型识别同一场景的两个不同视图应产生相似的表示)。其新颖之处在于,ViC-MAE 不是通过重复帧将图像人为地转化为假视频(一种常见的变通做法),而是将真实视频中相隔约一秒采样的帧视为同一场景的自然“增广视图”,将这些时间变化馈入对比学习目标,同时仍用掩码损失重建单个帧。团队还发现,将局部图块特征池化为全局表示,而非依赖单个分类词元,有助于防止模型在训练中坍缩。在标准基准上测试时,ViC-MAE 的 ViT-Large 版本在 ImageNet 上达到 87.1% 的 top-1 准确率,在富有挑战性的 Something-Something-v2 视频基准上达到 75.9%,在 ImageNet 上比可比的自监督方法 OmniMAE 高出约 2.4 个百分点,同时在视频任务上也胜过它——这一结果表明,经审慎使用的视频数据能够在不牺牲视频性能的前提下显著增强图像理解。
摘要
我们提出 ViC-MAE,一个将掩码自编码器(MAE)与对比学习相结合的模型。ViC-MAE 使用一个全局特征进行训练,该特征通过对在 MAE 重建损失下学习到的局部表示进行池化而得到,并在跨图像和视频帧的对比目标下利用这一表示。我们表明,在 ViC-MAE 下学习到的视觉表示能很好地泛化到视频和图像分类任务上。特别地,与近期提出的 OmniMAE 相比,ViC-MAE 在 Imagenet-1k 上取得了从视频到图像的最先进迁移学习性能:在使用相同数据训练时达到 86% 的 top-1 准确率(绝对提升 +1.3%),在使用额外数据训练时达到 87.1% 的 top-1 准确率(绝对提升 +2.4%)。与此同时,ViC-MAE 在视频基准上优于大多数其他方法,在富有挑战性的 Something-something-v2 视频基准上取得 75.9% 的 top-1 准确率。当在来自多种数据集组合的视频和图像上训练时,我们的方法在视频和图像分类基准之间保持了均衡的迁移学习性能,仅以微弱差距位居最佳监督方法之后。
详情
引用
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
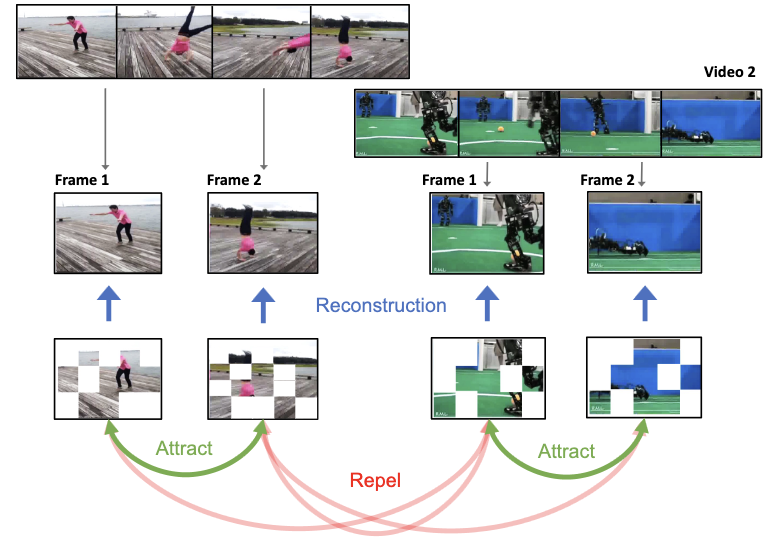
- 什么是 ViC-MAE?ViC-MAE 是一种自监督视觉表示学习方法,它将掩码自编码与对比学习相结合,使单个骨干网络能够学习对图像和视频都有用的特征。
- ViC-MAE 与以往的图像-视频预训练方法在使用视频上有何不同?ViC-MAE 不是将图像转化为重复帧的视频,而是将真实视频中相邻的帧视为自然的时间增广,并对齐它们的池化表示。
- 为什么要将掩码图像建模与对比学习结合?重建目标鼓励强大的局部图块特征,而对比目标则鼓励在增广图像和时间偏移的视频帧之间保持全局不变性。
- 池化在该方法中扮演什么角色?ViC-MAE 在对比分支之前将局部 ViT 特征池化为全局表示,论文表明这对于稳定训练很重要,并避免仅依赖分类词元。
- 有什么证据表明 ViC-MAE 学习到了均衡的图像和视频表示?论文报告了在 ImageNet、Kinetics-400、Places365、Something-Something-v2、若干下游图像分类数据集以及 COCO 检测和分割上的强迁移性能。
主要贡献
- 论文引入了一个统一的自监督框架,它结合掩码重建与对比对齐,从图像和视频两者进行训练。
- ViC-MAE 表明,视频帧能够作为图像级表示学习的有效时间增广,在不放弃视频性能的前提下改善从视频到图像的迁移。
- 该方法将对局部 MAE 特征的全局池化确定为稳定的对比掩码自编码器训练的一项实用设计选择。
- 在 ViT-Large 骨干网络下,ViC-MAE 达到 87.1% 的 ImageNet top-1 准确率和 75.9% 的 Something-Something-v2 top-1 准确率,在所报告的设置下优于 OmniMAE 等可比的自监督基线。
- 论文在图像分类、视频动作识别、目标检测和分割上提供了广泛的实证验证,使该贡献超越单一基准而具有实用价值。
局限与注意事项
- 最强的结果使用了大型 ViT 骨干网络和多数据集预训练,这对于现代基础模型式的视觉表示学习而言是典型做法,并有助于展示该方法的扩展行为。
- ViC-MAE 主要通过迁移和微调基准来评估,而非每一种可能的下游视频或图像任务,将更多领域留作有前景的后续评估。
- 该方法依赖于重建目标与对比目标之间的审慎平衡,但论文包含了关于池化、帧间隔、增广和数据混合的消融实验,使这些设计选择得以清晰呈现。
- 该方法改善了统一的图像-视频自监督,而特定任务的监督模型在某些个别基准上仍可能具有竞争力;这将 ViC-MAE 定位为一个强大的通用表示学习者,而非狭窄的专家。
- 论文聚焦于纯视觉预训练,因此在同一框架基础上扩展到文本、音频或更广泛的多模态对齐仍是自然的机会。
如何理解这一结果
这篇论文最好被理解为自监督图像-视频表示学习中一项有力且实用的进展:ViC-MAE 证明视频数据能够在保持出色视频性能的同时改善图像表示,并且它通过掩码自编码、时间对比学习和池化的局部特征这一简洁组合做到了这一点。