ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
新闻稿摘要
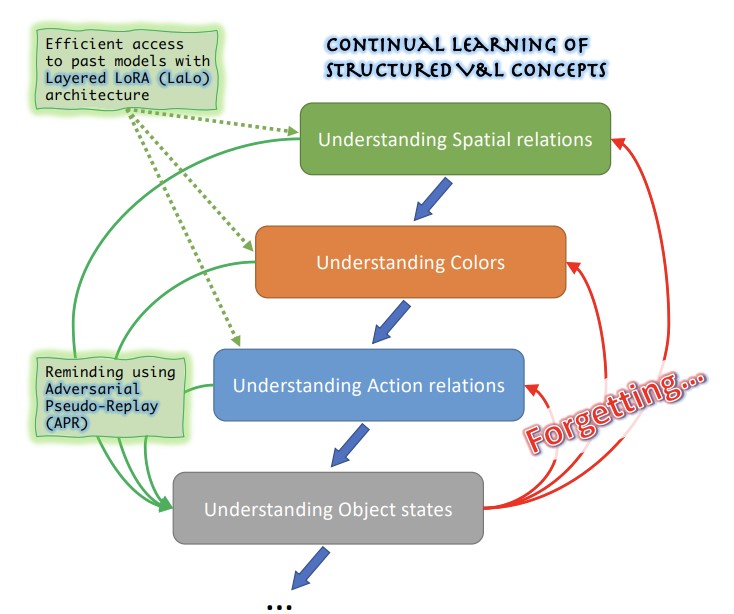
来自 MIT-IBM Watson AI Lab、佐治亚理工学院、莱斯大学、IBM Research 和斯坦福大学的研究人员攻克了大型视觉语言 AI 模型一个实际但尚未充分探索的问题:这些系统往往难以理解细致的关系性和描述性概念——例如物体的颜色、大小、空间位置和状态——而当工程师试图通过在新数据上微调模型来修复某一弱点时,模型往往会忘记如何处理先前已纠正的弱点,这一现象被称为灾难性遗忘。雪上加霜的是,用于识别和修复每个问题的数据往往是私有的,无法在各轮训练之间保留或重用。为应对这一点,团队创建了 ConStruct-VL,这是首个专门设计用于评估在无法访问先前任务数据、且在测试时不提供任何关于正在评估何种概念类型的提示的情况下,对这些结构化视觉语言概念进行持续学习的基准。他们还开发了两项互补的技术贡献:一种分层 LoRA(LaLo)架构,它为每个新任务在冻结的基础模型之上堆叠轻量级的低秩适配器模块,使系统在训练期间无需重新加载权重即可高效访问任何先前任务的模型;以及一种对抗伪重放(APR)方法,它利用那些过去的模型生成棘手的负训练样本——例如,微妙地改动一段文本描述,使其包含与配对图像不一致的颜色词——然后用这些样本来提醒当前模型它先前学过的内容。在从 Visual Genome 和 Visual Attributes in the Wild 数据集中抽取的多个任务序列上对 BLIP 视觉语言模型进行测试时,相比最优的竞争性无数据持续学习方法,该组合方法将平均遗忘减少了约五倍,并将最终准确率提升了多达 6.8 个百分点,同时仅使用完整模型约 2.8% 的参数——这些结果之所以重要,是因为它们表明在隐私敏感的现实部署中,存在一条可行的途径来持续修补 AI 模型,而不会损害先前的改进。
摘要
近来,大规模预训练的视觉语言(VL)基础模型在许多零样本下游任务中展现出卓越能力,仅凭短文本提示即可在识别对象方面取得有竞争力的结果。然而,研究也表明,VL 模型在结构化视觉语言概念(SVLC)推理方面仍然脆弱,例如识别物体属性、状态以及物体间关系的能力。这会导致推理错误,需要在错误发生时通过向 VL 模型教授缺失的 SVLC 技能来加以纠正;这通常必须使用发现问题所在的私有数据来进行,从而自然导向一种无数据的持续(无任务标识)VL 学习设置。在本工作中,我们引入了首个持续无数据结构化视觉语言概念学习(ConStruct-VL)基准,并表明它对许多现有的无数据持续学习策略而言都具有挑战性。因此,我们提出了一种无数据方法,其中包含一种名为对抗伪重放(Adversarial Pseudo-Replay,APR)的新方法,它从过去任务的模型中生成过去任务的对抗性提醒。为高效使用该方法,我们还提出了一种持续的参数高效分层 LoRA(Layered-LoRA,LaLo)神经架构,使训练时能够无内存成本地访问所有过去模型。我们表明,该方法以高达约 7% 的优势超越所有无数据方法,甚至达到了某些经验重放的水平(而经验重放在必须保护数据隐私的应用中是不可行的)。我们的代码已公开于 https://github.com/jamessealesmith/ConStruct-VL
详情
引用
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}