Where and Who? Automatic Semantic-Aware Person Composition
新闻稿摘要
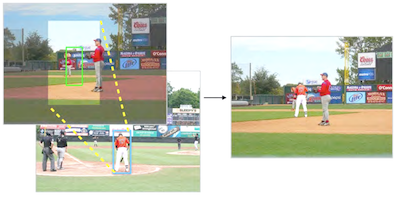
弗吉尼亚大学的研究人员构建了一个系统,它能够在无需任何关于放在何处或使用谁的人为指导的情况下,自动将一个看起来逼真的人物形象嵌入到一张照片中。大多数现有的照片合成工具处理的是融合边缘和匹配颜色这类技术性工作,却仍然把挑选前景主体、选择放置位置以及决定大小这些判断交给用户。这套新系统以计算方式应对这些判断:它在来自 MS-COCO 数据集的数万张带标注图像上训练一个分支卷积神经网络,教它在仅给定背景场景的情况下预测人物合理的位置和大小。一旦预测出一个边界框,系统便会在一个约 4,100 个手工分割的人物剪影组成的候选池中搜索,使用来自预训练 ResNet50 模型的深度特征来匹配整体场景类型和紧邻的局部环境,然后用 alpha 抠图(alpha matting)将选中的人物融合进去。在一项使用 Amazon Mechanical Turk 的众包用户研究中,人类评判者约有 44% 的时候将该系统的合成图判定为真实,而三种基线方法约为 18% 到 28%,不过真实照片仍然得到约 90% 的评分。当纹理和光照被剥离后,这一差距显著缩小,表明颜色和光照的不匹配——而非放置或人物选择——才是剩下的主要障碍。研究人员表示,这项工作代表着朝向可辅助平面设计师、电影制作者和分镜画师的工具迈出的早期一步,这些人目前要花费大量时间手工拼装此类场景。
摘要
图像合成(image compositing)是一种通过将一幅图像中的内容插入到另一幅图像中来生成逼真却虚假的影像的方法。以往的合成工作侧重于改善用户选定的前景片段与背景图像之间的外观兼容性(即颜色和光照一致性)。在本工作中,我们转而开发了一个全自动的合成模型,它在仅给定一幅输入背景图像的情况下,还能学会从一个大型集合中选择并变换兼容的前景片段。为简化任务,我们通过聚焦于人体实例合成来限定问题,这是因为人体片段与其背景表现出强相关性,并且存在大量带标注的数据可用。我们开发了一种新颖的分支卷积神经网络(CNN),它在给定背景图像的情况下联合预测候选人物位置。随后,我们使用预训练的深度特征表示从一个大型片段数据库中检索人物实例。实验结果表明,我们的模型能够生成在视觉上令人信服的合成图像。我们还开发了一个用户界面来展示我们方法的潜在应用。
详情
引用
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}