新闻稿摘要
莱斯大学和 Microsoft 的研究人员开发了一个名为 AutoVER 的系统,它通过将 AI 语言模型的猜测锚定到一个具体的知识库,而非任其生成任何看似合理的答案,从而大幅提升计算机识别图像中特定现实世界实体的能力——比如从一个几乎相同的飞机型号中区分出另一个。核心问题在于,现有的多模态 AI 系统在处理图像和文本时,在被问及细粒度识别问题(例如判断图中飞机是 ATR 42 还是 British Aerospace 146)时,往往会产生幻觉或给出错误特异性层级的答案。AutoVER 通过结合两种技术来解决这一问题:它使用对比学习方法训练模型从包含超过六百万条 Wikipedia 条目的数据库中检索视觉和语义上相似的候选实体,然后在答案生成期间,通过构建一棵前缀树来阻止任何会导致无效答案的 token 序列,从而将模型的输出限制为仅这些检索到的候选项。该系统在 Oven-Wiki 基准(一个专为此类视觉实体识别挑战而设计的大规模数据集)上进行了测试,将模型在训练中见过的实体上的准确率从约 32.7% 提升到 61.5%,同时在涉及未见实体和需要视觉推理的样本上,也优于像 Google 的 PaLI-17B 这样大得多的模型。这项工作之所以重要,是因为从图像中可靠地识别实体在从搜索引擎到无障碍工具等诸多领域都有实际应用,并且该方法证明了将检索与约束生成紧密耦合,比单纯地扩大模型规模并寄望它能给出足够具体的正确答案,是一条更可靠的路径。
摘要
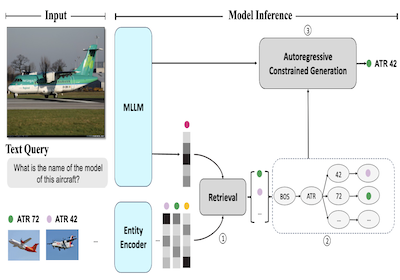
我们推出 AutoVER,一个用于视觉实体识别的自回归模型。我们的模型通过采用检索增强的约束生成,扩展了自回归的多模态大型语言模型。它在缓解域外实体上的低性能问题的同时,在需要视觉情境推理的查询上表现出色。我们的方法通过在硬负样本对上进行对比训练,并与序列到序列目标并行,学会在庞大的标签空间中区分相似实体,且无需外部检索器。在推理期间,一组检索到的候选答案通过移除无效的解码路径来显式引导语言生成。所提出的方法在最近提出的 Oven-Wiki 基准的不同数据集划分上取得了显著改进。在 Entity seen 划分上的准确率从 32.7% 提升到 61.5%。它在 unseen 和 query 划分上也以可观的两位数优势展现出卓越性能。
详情
引用
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 AutoVER?AutoVER 是一个用于视觉实体识别的自回归多模态语言模型,其答案必须锚定到大型知识库中的特定实体。
- 论文解决了什么问题?它解决了基于图像的细粒度实体识别问题,即模型必须区分视觉上相似的实体,并避免产生超出有效实体空间的幻觉答案。
- 这里的检索增强约束生成是如何工作的?AutoVER 检索出可能的实体,从这些候选项构建一棵动态前缀树,并约束解码,使生成仅沿着有效的实体名称 token 路径进行。
- 为什么要使用对比学习和硬负样本?模型通过视觉和知识相似的硬负样本来学习查询到实体的检索,帮助它区分共享外观或类别结构的实体。
- AutoVER 在哪里进行评估?论文在 Oven-Wiki 上进行评估,并在 A-OKVQA 的一个实体锚定子集上测试了零样本迁移。
主要贡献
- 论文引入 AutoVER,一个检索增强的自回归框架,用于将多模态语言模型的输出锚定到 Wikipedia 规模的视觉实体。
- 它将查询到实体的对比训练直接集成到多模态语言模型中,避免了对单独外部检索器的依赖。
- 约束解码机制确保生成的答案锚定于检索到的候选实体,直接减少了无效或未锚定的生成。
- 基于视觉相似性和知识库层级结构的硬负样本挖掘,提升了对视觉上相似实体的细粒度区分能力。
- AutoVER 显著提升了 Oven-Wiki 的性能,包括在所报告的对比中将 Entity seen 准确率从 32.7% 提升到 61.5%,并在 unseen 和 query 划分上优于更大的 PaLI 基线。
局限与注意事项
- AutoVER 依赖于实体知识库的覆盖范围和质量,这对于视觉实体识别是合适的,并使锚定目标变得明确。
- 该方法在约束解码之前会检索一组候选项,因此当检索遗漏时,非常罕见或视觉上模糊的实体仍然具有挑战性;论文通过实体侧的视觉特征和硬负样本训练直接解决了这一问题。
- 在 Wikipedia 规模上进行训练需要大量的数据和算力,但其成果是一个将大型知识库转化为可用视觉识别目标的实用框架。
- 论文在人工评估集上仍然显示出与“人工加搜索”性能之间的差距,这是衡量未来进展的有用基准,而非核心方法的弱点。
- AutoVER 专门用于实体锚定的答案,当所需输出应为精确命名实体时,它可作为更广泛的开放式 VQA 系统的补充。
如何理解这一结果
这篇论文最好被理解为对锚定多模态识别的有力贡献:AutoVER 表明,检索、对比实体学习和约束生成可以使语言模型的答案在 Wikipedia 规模的视觉实体识别中变得更加精确和可信。