Improving Progressive Generation with Decomposable Flow Matching
Zusammenfassung der Pressemitteilung
Forschende der Rice University und von Snap Inc. haben einen neuen Ansatz zur Generierung hochauflösender Bilder und Videos entwickelt, der die Qualität verbessert, ohne die Komplexität, die typischerweise mit mehrstufigen generativen Systemen verbunden ist. Die Arbeit, genannt Decomposable Flow Matching (DFM), adressiert eine bekannte Herausforderung der KI-Bildsynthese: Feine visuelle Details effizient zu generieren erfordert, die Aufgabe in von grob zu fein verlaufende Schritte zu zerlegen, aber bestehende Methoden dafür verlangen üblicherweise separate Modelle für jede Stufe, eigene Diffusionsprozesse oder aufwändige Übergaben zwischen den Stufen. DFM umgeht diese Komplikationen, indem es eine Standardtechnik namens Flow Matching unabhängig auf jede Ebene einer Multiskalen-Bildrepräsentation anwendet — im Wesentlichen eine Laplace-Pyramide, die ein Bild in Schichten zunehmender Detailtiefe zerlegt — und dabei durchgängig ein einziges gemeinsames Modell verwendet. Während des Trainings simuliert das System den progressiven Generierungsprozess, indem es für jede Stufe unterschiedliche Rauschpegel abtastet, und zur Inferenzzeit durchläuft ein einfacher Scheduler die Stufen nacheinander von grob zu fein. Getestet auf dem standardmäßigen ImageNet-1K-Benchmark bei einer Auflösung von 512 Pixeln, reduzierte DFM eine zentrale Qualitätsmetrik namens FDD um 35 % im Vergleich zu reinem Flow Matching und um 26 % gegenüber der besten konkurrierenden mehrstufigen Methode, bei gleichem Trainingsrechenaufwand. Die Forschenden wandten DFM auch auf das Feinabstimmen von FLUX an, einem großen Bildgenerierungsmodell auf kommerziellem Niveau, und stellten fest, dass es schneller zur Zielbildverteilung konvergierte als die Standard-Feinabstimmung und die FID-Werte um etwa 29 % senkte. Die Bedeutung der Arbeit liegt vor allem in ihrer Einfachheit: Sie liefert spürbare Qualitätsgewinne durch eine minimale Änderung an einer bestehenden Trainings-Pipeline, anstatt eine völlig neue Architektur oder eine separate Modellkaskade zu erfordern.
Zusammenfassung
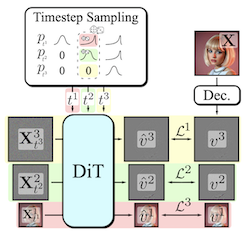
Die Generierung hochdimensionaler visueller Modalitäten ist eine rechenintensive Aufgabe. Eine gängige Lösung ist die progressive Generierung, bei der die Ausgaben in einer von grob zu fein verlaufenden, spektral autoregressiven Weise synthetisiert werden. Während Diffusionsmodelle von der von grob zu fein verlaufenden Natur des Entrauschens profitieren, werden explizite mehrstufige Architekturen nur selten übernommen. Diese Architekturen haben die Komplexität des Gesamtansatzes erhöht und die Notwendigkeit einer eigenen Diffusionsformulierung, von zerlegungsabhängigen Stufenübergängen, von Ad-hoc-Samplern oder einer Modellkaskade eingeführt. Unser Beitrag, Decomposable Flow Matching (DFM), ist ein einfaches und effektives Framework für die progressive Generierung visueller Medien. DFM wendet Flow Matching unabhängig auf jeder Ebene einer benutzerdefinierten Multiskalen-Repräsentation (wie etwa einer Laplace-Pyramide) an. Wie unsere Experimente zeigen, verbessert unser Ansatz die visuelle Qualität sowohl für Bilder als auch für Videos und erzielt überlegene Ergebnisse im Vergleich zu früheren mehrstufigen Frameworks. Auf Imagenet-1k 512px erreicht DFM Verbesserungen von 35,2 % bei den FDD-Werten gegenüber der Basisarchitektur und von 26,4 % gegenüber der leistungsstärksten Baseline, bei gleichem Trainingsrechenaufwand. Bei der Anwendung auf das Feinabstimmen großer Modelle wie FLUX zeigt DFM eine schnellere Konvergenzgeschwindigkeit zur Trainingsverteilung. Entscheidend ist, dass all diese Vorteile mit einem einzigen Modell, architektonischer Einfachheit und minimalen Änderungen an bestehenden Trainings-Pipelines erreicht werden.
Details
Zitation
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist Decomposable Flow Matching und welches Problem adressiert es? DFM ist ein Framework für progressive Generierung, das Flow Matching unabhängig über die Ebenen einer Multiskalen-Repräsentation anwendet und die von grob zu fein verlaufende Bild- und Videosynthese verbessert, ohne Modellkaskaden oder eigene Diffusionsprozesse zu erfordern.
- Wie generiert DFM Stichproben progressiv? Es zerlegt visuelle Daten in Stufen wie eine Laplace-Pyramide, weist jeder Stufe ihren eigenen Fluss-Zeitschritt zu und verwendet einen Sampler, der die Stufen von der groben Struktur zum feinen Detail voranschreitet.
- Warum ist DFM einfacher als viele frühere Methoden zur progressiven Generierung? Es behält ein einziges gemeinsames Modell und eine standardmäßige Flow-Matching-Formulierung bei und vermeidet separate Modelle pro Stufe, spezialisierte Sampler und komplizierte Übergangsmechanismen.
- Wie schneidet DFM bei Benchmarks zur Bildgenerierung ab? Auf ImageNet-1K bei 512px und 1024px übertrifft DFM Flow Matching, kaskadierte Baselines und Pyramidal Flow über die wichtigsten Metriken und Guidance-Einstellungen hinweg, die in der Arbeit berichtet werden.
- Hilft DFM beim Feinabstimmen großer Modelle? Ja, bei der Anwendung auf das Feinabstimmen von FLUX erreicht DFM bessere FID-, FDD- und CLIP-Ähnlichkeitswerte als die Standard-Feinabstimmung bei gleichem Trainingsrechenaufwand und zeigt eine schnellere Konvergenz zur Zielverteilung.
Wichtigste Beiträge
- Die Arbeit führt eine einfache Multiskalen-Erweiterung von Flow Matching ein, die die visuelle Generierung in einen zerlegbaren, von grob zu fein verlaufenden Prozess verwandelt und dabei einen einzigen gemeinsamen Generator beibehält.
- DFM unterstützt benutzerdefinierte Zerlegungen, wobei die Arbeit Laplace-Pyramiden verwendet und zugleich anmerkt, dass Wavelet-, DCT-, Fourier- oder Multiskalen-Autoencoder-Zerlegungen natürliche Alternativen sind.
- Die Methode umfasst eine detaillierte Analyse von Trainings-Zeitschrittverteilungen, Sampling-Schwellenwerten, Sampling-Schritten pro Stufe, Maskierung, Zerlegungswahlen und Strategien zur Rechenleistungszuteilung.
- Die Experimente zeigen starke Ergebnisse bei der Bildgenerierung auf ImageNet-1K und der Videogenerierung auf Kinetics-700, einschließlich der besten berichteten Werte unter den Baselines für progressive Generierung der Arbeit in den meisten Einstellungen.
- Das FLUX-Feinabstimmungsexperiment zeigt, dass DFM die Anpassung eines großen generativen Modells mit minimalen Änderungen an der Trainings-Pipeline verbessern kann.
Grenzen und Vorbehalte
- DFM führt zusätzliche Trainings- und Sampling-Hyperparameter ein, aber die Arbeit liefert umfangreiche Ablationen und praktische Hinweise, die zeigen, dass stabile Einstellungen über mehrere Experimente hinweg übertragbar sind.
- Die Leistung des Frameworks hängt von der Balance zwischen niederfrequenter Struktur und hochfrequentem Detail ab, sodass zukünftige Arbeiten automatische Scheduling-Strategien verfeinern können; die aktuellen Ergebnisse zeigen bereits, dass diese Balance große Qualitätsgewinne erzeugen kann.
- Die Hauptimplementierung verwendet Laplace-Zerlegungen und lässt andere Zerlegungen wie DCT, Wavelets und Multiskalen-Autoencoder als vielversprechende Erweiterungen offen, statt als Schwächen der Kernformulierung.
- Das Experiment mit großen Modellen konzentriert sich auf das Feinabstimmen von FLUX zu einer Zielverteilung, statt zu behaupten, das ursprüngliche Spitzenmodell in jeder Einsatzumgebung zu verbessern, was die Schlussfolgerung gut eingegrenzt und dennoch praktisch wertvoll hält.
- DFM ist am besten als ein Framework zur Trainingszeit für eine bessere progressive Generierung zu verstehen und nicht als ein eigenständiger, rein auf Inferenz ausgerichteter Beschleuniger, und seine Einfachheit macht es zu einer Ergänzung zukünftiger Systemarbeiten zu schnellerem Sampling und Deployment.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker und eleganter Beitrag zur progressiven visuellen Generierung lesen: DFM erfasst die Vorteile der von grob zu fein verlaufenden Synthese mit einem einzigen Flow-Matching-Modell, verbessert die Bild- und Videoqualität über Benchmarks hinweg und bietet einen praktischen Weg für ein besseres Feinabstimmen großer generativer Systeme.