Improving Progressive Generation with Decomposable Flow Matching
Resumo do comunicado de imprensa
Pesquisadores da Rice University e da Snap Inc. desenvolveram uma nova abordagem para gerar imagens e vídeos de alta resolução que melhora a qualidade sem a complexidade tipicamente associada a sistemas generativos multiestágio. O trabalho, chamado Decomposable Flow Matching (DFM), aborda um desafio conhecido na síntese de imagens por IA: gerar detalhes visuais finos de forma eficiente exige dividir a tarefa em etapas do mais grosseiro ao mais fino, mas os métodos existentes para isso geralmente demandam modelos separados para cada estágio, processos de difusão personalizados ou transições elaboradas entre estágios. O DFM contorna essas complicações ao aplicar uma técnica padrão chamada Flow Matching de forma independente a cada nível de uma representação multiescala da imagem — essencialmente uma pirâmide laplaciana que separa uma imagem em camadas de detalhe crescente — enquanto usa um único modelo compartilhado em todo o processo. Durante o treinamento, o sistema simula o processo de geração progressiva amostrando diferentes níveis de ruído para cada estágio e, na inferência, um agendador simples percorre os estágios sequencialmente do grosseiro ao fino. Testado no benchmark padrão ImageNet-1K com resolução de 512 pixels, o DFM reduziu uma métrica de qualidade fundamental chamada FDD em 35% em comparação com o Flow Matching puro e em 26% em relação ao melhor método multiestágio concorrente, usando a mesma quantidade de computação de treinamento. Os pesquisadores também aplicaram o DFM ao ajuste fino do FLUX, um grande modelo de geração de imagens de nível comercial, e descobriram que ele convergiu para a distribuição de imagens-alvo mais rápido do que o ajuste fino padrão, reduzindo as pontuações FID em cerca de 29%. A relevância do trabalho reside principalmente em sua simplicidade: ele entrega ganhos significativos de qualidade por meio de uma modificação mínima em um pipeline de treinamento existente, em vez de exigir uma arquitetura inteiramente nova ou uma cascata de modelos separada.
resumo
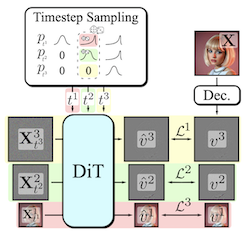
Gerar modalidades visuais de alta dimensionalidade é uma tarefa computacionalmente intensiva. Uma solução comum é a geração progressiva, em que as saídas são sintetizadas de maneira espectral autorregressiva, do grosseiro ao fino. Embora os modelos de difusão se beneficiem da natureza do grosseiro ao fino da remoção de ruído, arquiteturas multiestágio explícitas raramente são adotadas. Essas arquiteturas aumentaram a complexidade da abordagem como um todo, introduzindo a necessidade de uma formulação de difusão personalizada, de transições de estágio dependentes da decomposição, de samplers ad hoc ou de uma cascata de modelos. Nossa contribuição, o Decomposable Flow Matching (DFM), é um framework simples e eficaz para a geração progressiva de mídia visual. O DFM aplica o Flow Matching de forma independente em cada nível de uma representação multiescala definida pelo usuário (como a pirâmide laplaciana). Como mostram nossos experimentos, nossa abordagem melhora a qualidade visual tanto de imagens quanto de vídeos, apresentando resultados superiores em comparação a frameworks multiestágio anteriores. No Imagenet-1k 512px, o DFM alcança melhorias de 35,2% nas pontuações FDD em relação à arquitetura base e de 26,4% em relação à melhor baseline, sob a mesma computação de treinamento. Quando aplicado ao ajuste fino de grandes modelos, como o FLUX, o DFM apresenta uma convergência mais rápida para a distribuição de treinamento. Crucialmente, todas essas vantagens são obtidas com um único modelo, simplicidade arquitetural e modificações mínimas nos pipelines de treinamento existentes.
detalhes
citação
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o Decomposable Flow Matching e qual problema ele aborda? O DFM é um framework de geração progressiva que aplica o Flow Matching de forma independente ao longo dos níveis de uma representação multiescala, melhorando a síntese de imagens e vídeos do grosseiro ao fino sem exigir cascatas de modelos ou processos de difusão personalizados.
- Como o DFM gera amostras de forma progressiva? Ele decompõe os dados visuais em estágios, como uma pirâmide laplaciana, atribui a cada estágio seu próprio passo de tempo de fluxo e usa um sampler que avança pelos estágios da estrutura grosseira ao detalhe fino.
- Por que o DFM é mais simples do que muitos métodos de geração progressiva anteriores? Ele mantém um único modelo compartilhado e uma formulação padrão de Flow Matching, evitando modelos separados por estágio, samplers especializados e mecanismos de transição complicados.
- Como o DFM se sai em benchmarks de geração de imagens? No ImageNet-1K a 512px e 1024px, o DFM supera o Flow Matching, as baselines em cascata e o Pyramidal Flow nas principais métricas e configurações de guidance relatadas no artigo.
- O DFM ajuda no ajuste fino de modelos de larga escala? Sim, quando aplicado ao ajuste fino do FLUX, o DFM alcança melhor FID, FDD e similaridade CLIP do que o ajuste fino padrão sob a mesma computação de treinamento, mostrando uma convergência mais rápida para a distribuição-alvo.
Principais contribuições
- O artigo introduz uma extensão multiescala simples do Flow Matching que transforma a geração visual em um processo decomponível do grosseiro ao fino, mantendo um único gerador compartilhado.
- O DFM dá suporte a decomposições definidas pelo usuário, com o artigo usando pirâmides laplacianas ao mesmo tempo em que observa que decomposições por wavelet, DCT, Fourier ou autoencoders multiescala são alternativas naturais.
- O método inclui uma análise detalhada das distribuições de passos de tempo de treinamento, dos limiares de amostragem, dos passos de amostragem por estágio, do mascaramento, das escolhas de decomposição e das estratégias de alocação de computação.
- Os experimentos mostram resultados sólidos na geração de imagens do ImageNet-1K e na geração de vídeos do Kinetics-700, incluindo os melhores valores relatados entre as baselines de geração progressiva do artigo na maioria dos cenários.
- O experimento de ajuste fino do FLUX demonstra que o DFM pode melhorar a adaptação de um grande modelo generativo com mudanças mínimas no pipeline de treinamento.
Limitações e ressalvas
- O DFM introduz hiperparâmetros adicionais de treinamento e amostragem, mas o artigo fornece ablações extensas e orientações práticas mostrando que configurações estáveis se transferem entre múltiplos experimentos.
- O desempenho do framework depende do equilíbrio entre a estrutura de baixa frequência e o detalhe de alta frequência, então trabalhos futuros podem refinar políticas automáticas de agendamento; os resultados atuais já mostram que esse equilíbrio pode produzir grandes ganhos de qualidade.
- A implementação principal usa decomposições laplacianas, deixando outras decomposições como DCT, wavelets e autoencoders multiescala como extensões promissoras, e não como fraquezas da formulação central.
- O experimento com modelos grandes foca no ajuste fino do FLUX para uma distribuição-alvo, em vez de afirmar melhorar o modelo de fronteira original em todos os cenários de implantação, o que mantém a conclusão bem delimitada e ainda assim praticamente valiosa.
- O DFM é mais bem visto como um framework em tempo de treinamento para uma melhor geração progressiva, e não como um acelerador autônomo apenas de inferência, e sua simplicidade o torna complementar a futuros trabalhos de sistemas voltados a amostragem e implantação mais rápidas.
Como interpretar este resultado
Este artigo é mais bem compreendido como uma contribuição forte e elegante para a geração visual progressiva: o DFM captura os benefícios da síntese do grosseiro ao fino com um único modelo de Flow Matching, melhora a qualidade de imagens e vídeos em diversos benchmarks e oferece um caminho prático para um melhor ajuste fino de grandes sistemas generativos.