Improving Progressive Generation with Decomposable Flow Matching
Краткое изложение пресс-релиза
Исследователи из Rice University и Snap Inc. разработали новый подход к генерации изображений и видео высокого разрешения, который повышает качество без сложности, обычно связанной с многоэтапными генеративными системами. Работа под названием Decomposable Flow Matching (DFM) решает известную проблему в ИИ-синтезе изображений: эффективная генерация тонких визуальных деталей требует разбиения задачи на шаги от грубого к точному, но существующие методы для этого обычно требуют отдельных моделей для каждого этапа, специальных диффузионных процессов или сложных передач между этапами. DFM обходит эти осложнения, применяя стандартную технику Flow Matching независимо к каждому уровню многомасштабного представления изображения — по сути, пирамиды Лапласа, которая разделяет изображение на слои возрастающей детализации, — используя при этом единую общую модель повсюду. Во время обучения система имитирует процесс прогрессивной генерации, сэмплируя разные уровни шума для каждого этапа, а на этапе инференса простой планировщик последовательно проходит через этапы от грубого к точному. При тестировании на стандартном бенчмарке ImageNet-1K с разрешением 512 пикселей DFM снизил ключевую метрику качества FDD на 35% по сравнению с обычным Flow Matching и на 26% относительно лучшего конкурирующего многоэтапного метода при том же объёме вычислений на обучение. Исследователи также применили DFM к дообучению FLUX, большой коммерческого уровня модели генерации изображений, и обнаружили, что она сходится к целевому распределению изображений быстрее стандартного дообучения, снижая показатели FID примерно на 29%. Значимость работы заключается главным образом в её простоте: она обеспечивает ощутимый прирост качества за счёт минимального изменения существующего конвейера обучения, а не требует совершенно новой архитектуры или отдельного каскада моделей.
аннотация
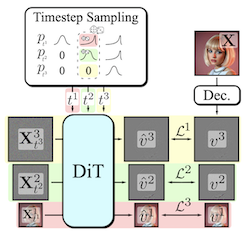
Генерация высокоразмерных визуальных модальностей — вычислительно затратная задача. Распространённое решение — прогрессивная генерация, при которой выходные данные синтезируются от грубого к точному в спектральной авторегрессионной манере. Хотя диффузионные модели выигрывают от природы шумоподавления, идущего от грубого к точному, явные многоэтапные архитектуры применяются редко. Эти архитектуры повышают сложность всего подхода, порождая необходимость в специальной формулировке диффузии, переходах между этапами, зависящих от декомпозиции, специализированных сэмплерах или каскаде моделей. Наш вклад — Decomposable Flow Matching (DFM) — это простой и эффективный фреймворк для прогрессивной генерации визуальных медиа. DFM применяет Flow Matching независимо на каждом уровне заданного пользователем многомасштабного представления (например, пирамиды Лапласа). Как показывают наши эксперименты, наш подход улучшает визуальное качество как для изображений, так и для видео, демонстрируя превосходные результаты по сравнению с прежними многоэтапными фреймворками. На ImageNet-1k 512px DFM достигает улучшения на 35,2% по показателю FDD относительно базовой архитектуры и на 26,4% относительно наилучшей базовой модели при тех же вычислительных затратах на обучение. При применении к дообучению больших моделей, таких как FLUX, DFM демонстрирует более высокую скорость сходимости к обучающему распределению. Важно, что все эти преимущества достигаются с одной моделью, архитектурной простотой и минимальными изменениями существующих конвейеров обучения.
подробности
цитирование
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое Decomposable Flow Matching и какую проблему он решает? DFM — это фреймворк прогрессивной генерации, который применяет Flow Matching независимо на уровнях многомасштабного представления, улучшая синтез изображений и видео от грубого к точному без необходимости в каскадах моделей или специальных диффузионных процессах.
- Как DFM генерирует сэмплы прогрессивно? Он декомпозирует визуальные данные на этапы, такие как пирамида Лапласа, назначает каждому этапу собственный временной шаг потока (flow timestep) и использует сэмплер, который продвигает этапы от грубой структуры к тонкой детали.
- Почему DFM проще многих прежних методов прогрессивной генерации? Он сохраняет единую общую модель и стандартную формулировку Flow Matching, избегая отдельных моделей для каждого этапа, специализированных сэмплеров и сложных механизмов перехода.
- Как DFM показывает себя на бенчмарках генерации изображений? На ImageNet-1K при 512px и 1024px DFM превосходит Flow Matching, каскадные базовые модели и Pyramidal Flow по основным метрикам и настройкам guidance, представленным в статье.
- Помогает ли DFM при дообучении крупномасштабных моделей? Да, при применении к дообучению FLUX DFM достигает лучших FID, FDD и сходства CLIP, чем стандартное дообучение, при тех же вычислительных затратах на обучение, демонстрируя более быструю сходимость к целевому распределению.
Основные вклады
- Статья представляет простое многомасштабное расширение Flow Matching, которое превращает визуальную генерацию в декомпозируемый процесс от грубого к точному, сохраняя при этом один общий генератор.
- DFM поддерживает заданные пользователем декомпозиции, при этом в статье используются пирамиды Лапласа, и отмечается, что вейвлет-, DCT-, Фурье- или многомасштабные автоэнкодерные декомпозиции являются естественными альтернативами.
- Метод включает детальный анализ распределений временных шагов обучения, порогов сэмплирования, числа шагов сэмплирования на этап, маскирования, выбора декомпозиции и стратегий распределения вычислений.
- Эксперименты показывают сильные результаты на генерации изображений ImageNet-1K и генерации видео Kinetics-700, включая лучшие из заявленных значений среди базовых моделей прогрессивной генерации в статье в большинстве настроек.
- Эксперимент с дообучением FLUX демонстрирует, что DFM может улучшить адаптацию большой генеративной модели при минимальных изменениях конвейера обучения.
Ограничения и предостережения
- DFM вводит дополнительные гиперпараметры обучения и сэмплирования, но статья предоставляет обширные абляции и практические рекомендации, показывающие, что стабильные настройки переносятся между несколькими экспериментами.
- Производительность фреймворка зависит от баланса между низкочастотной структурой и высокочастотной деталью, поэтому будущая работа может уточнить автоматические политики планирования; текущие результаты уже показывают, что этот баланс способен давать большой прирост качества.
- Основная реализация использует декомпозиции Лапласа, оставляя другие декомпозиции, такие как DCT, вейвлеты и многомасштабные автоэнкодеры, в качестве многообещающих расширений, а не слабостей базовой формулировки.
- Эксперимент с большой моделью сосредоточен на дообучении FLUX к целевому распределению, а не на заявлении об улучшении исходной передовой модели в любом сценарии развёртывания, что делает вывод чётко ограниченным и при этом практически ценным.
- DFM лучше всего рассматривать как фреймворк времени обучения для лучшей прогрессивной генерации, а не как самостоятельный ускоритель только для инференса, и его простота делает его дополняющим будущие системные работы по более быстрому сэмплированию и развёртыванию.
Как интерпретировать этот результат
Эту статью лучше всего рассматривать как сильный и изящный вклад в прогрессивную визуальную генерацию: DFM передаёт преимущества синтеза от грубого к точному с помощью одной модели Flow Matching, улучшает качество изображений и видео на разных бенчмарках и предлагает практичный путь к лучшему дообучению больших генеративных систем.