Improving Progressive Generation with Decomposable Flow Matching
Resumen de prensa
Investigadores de la Universidad Rice y Snap Inc. han desarrollado un nuevo enfoque para generar imágenes y videos de alta resolución que mejora la calidad sin la complejidad típicamente asociada con los sistemas generativos multietapa. El trabajo, llamado Decomposable Flow Matching (DFM), aborda un desafío conocido en la síntesis de imágenes por IA: generar detalle visual fino de manera eficiente requiere dividir la tarea en pasos de lo grueso a lo fino, pero los métodos existentes para hacerlo suelen exigir modelos separados para cada etapa, procesos de difusión personalizados o complejos traspasos entre etapas. DFM evita estas complicaciones aplicando una técnica estándar llamada Flow Matching de manera independiente a cada nivel de una representación de imagen multiescala —esencialmente una pirámide laplaciana que separa una imagen en capas de detalle creciente— mientras utiliza un único modelo compartido en todo el proceso. Durante el entrenamiento, el sistema simula el proceso de generación progresiva muestreando diferentes niveles de ruido para cada etapa, y en el momento de la inferencia un planificador simple avanza por las etapas de manera secuencial, de lo grueso a lo fino. Probado en la prueba comparativa estándar ImageNet-1K a una resolución de 512 píxeles, DFM redujo en un 35 % una métrica de calidad clave llamada FDD en comparación con Flow Matching simple, y en un 26 % respecto al mejor método multietapa competidor, utilizando la misma cantidad de cómputo de entrenamiento. Los investigadores también aplicaron DFM al ajuste fino de FLUX, un modelo de generación de imágenes grande de calidad comercial, y descubrieron que convergía a la distribución de imágenes objetivo más rápido que el ajuste fino estándar, reduciendo las puntuaciones FID en aproximadamente un 29 %. La importancia del trabajo radica principalmente en su simplicidad: logra mejoras de calidad significativas mediante una modificación mínima a una canalización de entrenamiento existente, en lugar de requerir una arquitectura totalmente nueva o una cascada de modelos separados.
resumen
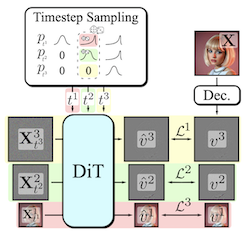
Generar modalidades visuales de alta dimensión es una tarea computacionalmente intensiva. Una solución común es la generación progresiva, donde las salidas se sintetizan de manera autorregresiva espectral, de lo grueso a lo fino. Si bien los modelos de difusión se benefician de la naturaleza de grueso a fino del proceso de eliminación de ruido, rara vez se adoptan arquitecturas multietapa explícitas. Estas arquitecturas han aumentado la complejidad del enfoque general, introduciendo la necesidad de una formulación de difusión personalizada, transiciones de etapa dependientes de la descomposición, muestreadores ad-hoc o una cascada de modelos. Nuestra contribución, Decomposable Flow Matching (DFM), es un marco simple y eficaz para la generación progresiva de medios visuales. DFM aplica Flow Matching de manera independiente en cada nivel de una representación multiescala definida por el usuario (como una pirámide laplaciana). Como muestran nuestros experimentos, nuestro enfoque mejora la calidad visual tanto de imágenes como de videos, ofreciendo resultados superiores en comparación con marcos multietapa anteriores. En Imagenet-1k 512px, DFM logra mejoras del 35,2 % en las puntuaciones FDD sobre la arquitectura base y del 26,4 % sobre la línea base de mejor rendimiento, con el mismo cómputo de entrenamiento. Cuando se aplica al ajuste fino de modelos grandes, como FLUX, DFM muestra una velocidad de convergencia más rápida hacia la distribución de entrenamiento. De forma crucial, todas estas ventajas se logran con un solo modelo, simplicidad arquitectónica y modificaciones mínimas a las canalizaciones de entrenamiento existentes.
detalles
cita
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es Decomposable Flow Matching y qué problema aborda? DFM es un marco de generación progresiva que aplica Flow Matching de manera independiente en los niveles de una representación multiescala, mejorando la síntesis de imágenes y videos de lo grueso a lo fino sin requerir cascadas de modelos ni procesos de difusión personalizados.
- ¿Cómo genera DFM muestras de forma progresiva? Descompone los datos visuales en etapas, como una pirámide laplaciana, asigna a cada etapa su propio paso temporal de flujo y utiliza un muestreador que avanza por las etapas desde la estructura gruesa hasta el detalle fino.
- ¿Por qué DFM es más simple que muchos métodos de generación progresiva anteriores? Mantiene un único modelo compartido y una formulación estándar de Flow Matching, evitando modelos separados por etapa, muestreadores especializados y mecanismos de transición complicados.
- ¿Cómo se desempeña DFM en las pruebas comparativas de generación de imágenes? En ImageNet-1K a 512px y 1024px, DFM supera a Flow Matching, a las líneas base en cascada y a Pyramidal Flow en las principales métricas y configuraciones de guía reportadas en el artículo.
- ¿Ayuda DFM al ajuste fino de modelos a gran escala? Sí; cuando se aplica al ajuste fino de FLUX, DFM alcanza mejores valores de FID, FDD y similitud CLIP que el ajuste fino estándar con el mismo cómputo de entrenamiento, mostrando una convergencia más rápida hacia la distribución objetivo.
Contribuciones principales
- El artículo introduce una sencilla extensión multiescala de Flow Matching que convierte la generación visual en un proceso descomponible de lo grueso a lo fino, manteniendo un único generador compartido.
- DFM admite descomposiciones definidas por el usuario; el artículo utiliza pirámides laplacianas, señalando al mismo tiempo que las descomposiciones por wavelet, DCT, Fourier o autoencoders multiescala son alternativas naturales.
- El método incluye un análisis detallado de las distribuciones de los pasos temporales de entrenamiento, los umbrales de muestreo, los pasos de muestreo por etapa, el enmascaramiento, las elecciones de descomposición y las estrategias de asignación de cómputo.
- Los experimentos muestran resultados sólidos en la generación de imágenes de ImageNet-1K y en la generación de video de Kinetics-700, incluyendo los mejores valores reportados entre las líneas base de generación progresiva del artículo en la mayoría de las configuraciones.
- El experimento de ajuste fino de FLUX demuestra que DFM puede mejorar la adaptación de un modelo generativo grande con cambios mínimos en la canalización de entrenamiento.
Limitaciones y advertencias
- DFM introduce hiperparámetros adicionales de entrenamiento y muestreo, pero el artículo ofrece extensos estudios de ablación y orientación práctica que muestran que las configuraciones estables se transfieren entre múltiples experimentos.
- El rendimiento del marco depende de equilibrar la estructura de baja frecuencia y el detalle de alta frecuencia, por lo que el trabajo futuro puede refinar las políticas de programación automática; los resultados actuales ya muestran que este equilibrio puede producir grandes mejoras de calidad.
- La implementación principal utiliza descomposiciones laplacianas, dejando otras descomposiciones como DCT, wavelets y autoencoders multiescala como extensiones prometedoras en lugar de debilidades de la formulación central.
- El experimento con modelos grandes se centra en ajustar FLUX a una distribución objetivo, en lugar de afirmar que mejora el modelo de frontera original en todos los escenarios de despliegue, lo que mantiene la conclusión bien acotada y aun así prácticamente valiosa.
- DFM se entiende mejor como un marco en tiempo de entrenamiento para una mejor generación progresiva que como un acelerador independiente solo de inferencia, y su simplicidad lo hace complementario a futuros trabajos de sistemas sobre muestreo y despliegue más rápidos.
Cómo interpretar este resultado
Este artículo se entiende mejor como una contribución sólida y elegante a la generación visual progresiva: DFM captura los beneficios de la síntesis de lo grueso a lo fino con un único modelo de Flow Matching, mejora la calidad de imágenes y videos en distintas pruebas comparativas y ofrece un camino práctico para un mejor ajuste fino de sistemas generativos grandes.