Improving Progressive Generation with Decomposable Flow Matching
Sintesi del comunicato stampa
I ricercatori della Rice University e di Snap Inc. hanno sviluppato un nuovo approccio alla generazione di immagini e video ad alta risoluzione che migliora la qualità senza la complessità tipicamente associata ai sistemi generativi multi-stadio. Il lavoro, chiamato Decomposable Flow Matching (DFM), affronta una sfida nota nella sintesi di immagini con l'IA: generare dettagli visivi fini in modo efficiente richiede di suddividere il compito in passi dal più grossolano al più fine, ma i metodi esistenti per farlo richiedono di solito modelli separati per ogni stadio, processi di diffusione personalizzati o elaborati passaggi di consegna tra gli stadi. DFM aggira queste complicazioni applicando una tecnica standard chiamata Flow Matching in modo indipendente a ciascun livello di una rappresentazione multiscala dell'immagine — essenzialmente una piramide laplaciana che separa un'immagine in livelli di dettaglio crescente — utilizzando al contempo un unico modello condiviso. Durante l'addestramento, il sistema simula il processo di generazione progressiva campionando diversi livelli di rumore per ogni stadio, e in fase di inferenza un semplice scheduler attraversa gli stadi in sequenza dal grossolano al fine. Testato sul benchmark standard ImageNet-1K alla risoluzione di 512 pixel, DFM ha ridotto del 35% una metrica chiave di qualità chiamata FDD rispetto al Flow Matching semplice e del 26% rispetto al miglior metodo multi-stadio concorrente, utilizzando la stessa quantità di risorse di calcolo per l'addestramento. I ricercatori hanno applicato DFM anche al fine-tuning di FLUX, un grande modello di generazione di immagini di livello commerciale, e hanno scoperto che convergeva alla distribuzione di immagini obiettivo più velocemente del fine-tuning standard, riducendo i punteggi FID di circa il 29%. L'importanza del lavoro risiede principalmente nella sua semplicità: offre guadagni di qualità significativi attraverso una modifica minima a una pipeline di addestramento esistente, anziché richiedere un'architettura completamente nuova o una cascata di modelli separata.
abstract
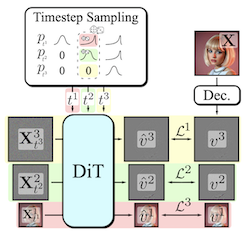
Generare modalità visive ad alta dimensionalità è un compito computazionalmente intensivo. Una soluzione comune è la generazione progressiva, in cui gli output sono sintetizzati in modo autoregressivo spettrale dal grossolano al fine. Sebbene i modelli di diffusione traggano beneficio dalla natura dal grossolano al fine del denoising, le architetture esplicitamente multi-stadio sono raramente adottate. Queste architetture hanno aumentato la complessità dell'approccio complessivo, introducendo la necessità di una formulazione di diffusione personalizzata, di transizioni di stadio dipendenti dalla decomposizione, di sampler ad hoc o di una cascata di modelli. Il nostro contributo, Decomposable Flow Matching (DFM), è un framework semplice ed efficace per la generazione progressiva di media visivi. DFM applica il Flow Matching in modo indipendente a ciascun livello di una rappresentazione multi-scala definita dall'utente (come la piramide laplaciana). Come mostrato dai nostri esperimenti, il nostro approccio migliora la qualità visiva sia per le immagini sia per i video, presentando risultati superiori rispetto ai precedenti framework multi-stadio. Su Imagenet-1k 512px, DFM ottiene miglioramenti del 35.2% nei punteggi FDD rispetto all'architettura di base e del 26.4% rispetto al miglior baseline, a parità di risorse di calcolo per l'addestramento. Quando applicato al fine-tuning di grandi modelli, come FLUX, DFM mostra una velocità di convergenza più rapida verso la distribuzione di addestramento. Aspetto cruciale: tutti questi vantaggi sono ottenuti con un singolo modello, con semplicità architetturale e modifiche minime alle pipeline di addestramento esistenti.
dettagli
citazione
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Cos'è il Decomposable Flow Matching e quale problema affronta? DFM è un framework di generazione progressiva che applica il Flow Matching in modo indipendente ai livelli di una rappresentazione multiscala, migliorando la sintesi di immagini e video dal grossolano al fine senza richiedere cascate di modelli o processi di diffusione personalizzati.
- Come genera DFM i campioni in modo progressivo? Decompone i dati visivi in stadi come una piramide laplaciana, assegna a ciascuno stadio il proprio timestep di flusso e utilizza un sampler che fa avanzare gli stadi dalla struttura grossolana al dettaglio fine.
- Perché DFM è più semplice di molti metodi di generazione progressiva precedenti? Mantiene un unico modello condiviso e una formulazione standard di Flow Matching, evitando modelli separati per ogni stadio, sampler specializzati e meccanismi di transizione complicati.
- Come si comporta DFM sui benchmark di generazione di immagini? Su ImageNet-1K a 512px e 1024px, DFM supera il Flow Matching, i baseline a cascata e il Pyramidal Flow nelle principali metriche e impostazioni di guidance riportate nell'articolo.
- DFM aiuta il fine-tuning di modelli su larga scala? Sì, quando applicato al fine-tuning di FLUX, DFM raggiunge FID, FDD e similarità CLIP migliori rispetto al fine-tuning standard a parità di risorse di calcolo per l'addestramento, mostrando una convergenza più rapida verso la distribuzione obiettivo.
Principali contributi
- L'articolo introduce una semplice estensione multiscala del Flow Matching che trasforma la generazione visiva in un processo decomponibile dal grossolano al fine mantenendo un unico generatore condiviso.
- DFM supporta decomposizioni definite dall'utente: l'articolo utilizza piramidi laplaciane, osservando al contempo che decomposizioni wavelet, DCT, Fourier o tramite autoencoder multiscala sono alternative naturali.
- Il metodo include un'analisi dettagliata delle distribuzioni dei timestep di addestramento, delle soglie di campionamento, dei passi di campionamento per stadio, del masking, delle scelte di decomposizione e delle strategie di allocazione del calcolo.
- Gli esperimenti mostrano risultati solidi nella generazione di immagini su ImageNet-1K e nella generazione di video su Kinetics-700, inclusi i migliori valori riportati tra i baseline di generazione progressiva dell'articolo nella maggior parte dei contesti.
- L'esperimento di fine-tuning di FLUX dimostra che DFM può migliorare l'adattamento di un grande modello generativo con modifiche minime alla pipeline di addestramento.
Limiti e avvertenze
- DFM introduce ulteriori iperparametri di addestramento e di campionamento, ma l'articolo fornisce estesi studi di ablazione e indicazioni pratiche che mostrano come impostazioni stabili si trasferiscano attraverso molteplici esperimenti.
- Le prestazioni del framework dipendono dal bilanciamento tra struttura a bassa frequenza e dettaglio ad alta frequenza, quindi i lavori futuri possono affinare le politiche di scheduling automatico; i risultati attuali mostrano già che questo equilibrio può produrre ampi guadagni di qualità.
- L'implementazione principale utilizza decomposizioni laplaciane, lasciando altre decomposizioni come DCT, wavelet e autoencoder multiscala come promettenti estensioni anziché come debolezze della formulazione di base.
- L'esperimento sul grande modello si concentra sul fine-tuning di FLUX verso una distribuzione obiettivo anziché sostenere di migliorare il modello di frontiera originale in ogni contesto di deployment, il che mantiene la conclusione ben delimitata e comunque praticamente preziosa.
- DFM è meglio inteso come un framework in fase di addestramento per una migliore generazione progressiva piuttosto che come un acceleratore autonomo solo per l'inferenza, e la sua semplicità lo rende complementare a futuri lavori di sistema su campionamento e deployment più veloci.
Come interpretare questo risultato
Questo articolo si legge al meglio come un contributo solido ed elegante alla generazione visiva progressiva: DFM cattura i benefici della sintesi dal grossolano al fine con un unico modello di Flow Matching, migliora la qualità di immagini e video su diversi benchmark e offre una via pratica per un migliore fine-tuning di grandi sistemi generativi.