Improving Progressive Generation with Decomposable Flow Matching
Résumé du communiqué de presse
Des chercheurs de l'université Rice et de Snap Inc. ont mis au point une nouvelle approche pour générer des images et des vidéos en haute résolution qui améliore la qualité sans la complexité habituellement associée aux systèmes génératifs multi-étapes. Ce travail, baptisé Decomposable Flow Matching (DFM), s'attaque à un défi connu de la synthèse d'images par IA : générer efficacement des détails visuels fins nécessite de décomposer la tâche en étapes du plus grossier au plus fin, mais les méthodes existantes pour y parvenir exigent généralement des modèles distincts pour chaque étape, des processus de diffusion sur mesure ou des transitions élaborées entre les étapes. DFM contourne ces complications en appliquant une technique standard appelée Flow Matching de manière indépendante à chaque niveau d'une représentation multi-échelle de l'image — essentiellement une pyramide laplacienne qui décompose une image en couches de détail croissant — tout en utilisant un seul modèle partagé d'un bout à l'autre. Pendant l'entraînement, le système simule le processus de génération progressive en échantillonnant différents niveaux de bruit pour chaque étape, et au moment de l'inférence, un planificateur simple parcourt les étapes séquentiellement du grossier au fin. Testé sur le banc d'essai standard ImageNet-1K à une résolution de 512 pixels, DFM a réduit une métrique de qualité clé appelée FDD de 35 % par rapport au Flow Matching ordinaire et de 26 % par rapport à la meilleure méthode multi-étapes concurrente, en utilisant la même quantité de puissance de calcul d'entraînement. Les chercheurs ont également appliqué DFM à l'affinage de FLUX, un grand modèle de génération d'images de qualité commerciale, et ont constaté qu'il convergeait vers la distribution d'images cible plus rapidement que l'affinage standard, réduisant les scores FID d'environ 29 %. L'importance de ce travail réside principalement dans sa simplicité : il apporte des gains de qualité substantiels grâce à une modification minimale d'un pipeline d'entraînement existant plutôt que de nécessiter une architecture entièrement nouvelle ou une cascade de modèles distincts.
résumé
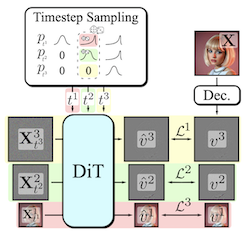
Générer des modalités visuelles de haute dimension est une tâche coûteuse en calcul. Une solution courante est la génération progressive, où les sorties sont synthétisées de manière autorégressive spectrale, du grossier au fin. Bien que les modèles de diffusion profitent de la nature du débruitage allant du grossier au fin, les architectures multi-étapes explicites sont rarement adoptées. Ces architectures ont accru la complexité de l'approche globale, introduisant le besoin d'une formulation de diffusion sur mesure, de transitions d'étapes dépendantes de la décomposition, d'échantillonneurs ad hoc ou d'une cascade de modèles. Notre contribution, Decomposable Flow Matching (DFM), est un cadre simple et efficace pour la génération progressive de médias visuels. DFM applique le Flow Matching de manière indépendante à chaque niveau d'une représentation multi-échelle définie par l'utilisateur (telle qu'une pyramide laplacienne). Comme le montrent nos expériences, notre approche améliore la qualité visuelle aussi bien pour les images que pour les vidéos, offrant des résultats supérieurs à ceux des cadres multi-étapes antérieurs. Sur ImageNet-1k 512px, DFM obtient des améliorations de 35,2 % des scores FDD par rapport à l'architecture de base et de 26,4 % par rapport à la meilleure référence, à puissance de calcul d'entraînement égale. Appliqué à l'affinage de grands modèles, tels que FLUX, DFM montre une convergence plus rapide vers la distribution d'entraînement. De manière cruciale, tous ces avantages sont obtenus avec un seul modèle, une simplicité architecturale et des modifications minimales des pipelines d'entraînement existants.
détails
citation
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce que Decomposable Flow Matching et quel problème résout-il ? DFM est un cadre de génération progressive qui applique le Flow Matching de manière indépendante à travers les niveaux d'une représentation multi-échelle, améliorant la synthèse d'images et de vidéos du grossier au fin sans nécessiter de cascades de modèles ni de processus de diffusion sur mesure.
- Comment DFM génère-t-il les échantillons de manière progressive ? Il décompose les données visuelles en étapes telles qu'une pyramide laplacienne, attribue à chaque étape son propre pas de temps de flux et utilise un échantillonneur qui fait progresser les étapes de la structure grossière vers le détail fin.
- Pourquoi DFM est-il plus simple que de nombreuses méthodes de génération progressive antérieures ? Il conserve un seul modèle partagé et une formulation standard de Flow Matching, évitant des modèles distincts par étape, des échantillonneurs spécialisés et des mécanismes de transition compliqués.
- Quelles sont les performances de DFM sur les bancs d'essai de génération d'images ? Sur ImageNet-1K en 512px et 1024px, DFM surpasse le Flow Matching, les références en cascade et le Pyramidal Flow sur les principales métriques et configurations de guidage rapportées dans l'article.
- DFM aide-t-il à l'affinage de modèles à grande échelle ? Oui, appliqué à l'affinage de FLUX, DFM atteint de meilleures valeurs de FID, FDD et de similarité CLIP que l'affinage standard à puissance de calcul d'entraînement égale, montrant une convergence plus rapide vers la distribution cible.
Principales contributions
- L'article introduit une extension multi-échelle simple du Flow Matching qui transforme la génération visuelle en un processus décomposable du grossier au fin tout en conservant un seul générateur partagé.
- DFM prend en charge des décompositions définies par l'utilisateur, l'article utilisant des pyramides laplaciennes tout en notant que les décompositions en ondelettes, DCT, Fourier ou par autoencodeur multi-échelle sont des alternatives naturelles.
- La méthode inclut une analyse détaillée des distributions de pas de temps d'entraînement, des seuils d'échantillonnage, des pas d'échantillonnage par étape, du masquage, des choix de décomposition et des stratégies d'allocation de calcul.
- Les expériences montrent de solides résultats sur la génération d'images ImageNet-1K et la génération vidéo Kinetics-700, y compris les meilleures valeurs rapportées parmi les références de génération progressive de l'article dans la plupart des configurations.
- L'expérience d'affinage de FLUX démontre que DFM peut améliorer l'adaptation d'un grand modèle génératif avec des modifications minimales du pipeline d'entraînement.
Limites et mises en garde
- DFM introduit des hyperparamètres d'entraînement et d'échantillonnage supplémentaires, mais l'article fournit des ablations approfondies et des conseils pratiques montrant que des réglages stables se transfèrent à travers plusieurs expériences.
- La performance du cadre dépend de l'équilibre entre la structure basse fréquence et le détail haute fréquence, de sorte que les travaux futurs pourront affiner les politiques de planification automatique ; les résultats actuels montrent déjà que cet équilibre peut produire d'importants gains de qualité.
- L'implémentation principale utilise des décompositions laplaciennes, laissant d'autres décompositions telles que la DCT, les ondelettes et les autoencodeurs multi-échelles comme extensions prometteuses plutôt que comme faiblesses de la formulation de base.
- L'expérience sur les grands modèles se concentre sur l'affinage de FLUX vers une distribution cible plutôt que de prétendre améliorer le modèle de pointe d'origine dans toutes les configurations de déploiement, ce qui maintient la conclusion bien délimitée tout en restant utile en pratique.
- DFM se conçoit avant tout comme un cadre d'entraînement pour une meilleure génération progressive plutôt que comme un accélérateur autonome au moment de l'inférence, et sa simplicité le rend complémentaire des travaux systèmes futurs sur l'échantillonnage et le déploiement plus rapides.
Comment interpréter ce résultat
Cet article se lit avant tout comme une contribution solide et élégante à la génération visuelle progressive : DFM capture les bénéfices de la synthèse du grossier au fin avec un seul modèle de Flow Matching, améliore la qualité des images et des vidéos sur l'ensemble des bancs d'essai et offre une voie pratique pour un meilleur affinage des grands systèmes génératifs.