Improving Progressive Generation with Decomposable Flow Matching
プレスリリース要約
Rice大学とSnap Inc.の研究者らは、多段階生成システムに通常伴う複雑さを伴わずに品質を向上させる、高解像度の画像と動画を生成するための新しいアプローチを開発しました。Decomposable Flow Matching(DFM)と呼ばれるこの研究は、AI画像合成における既知の課題に対処します。すなわち、細かい視覚的詳細を効率的に生成するには、タスクを粗いものから細かいものへのステップに分解する必要がありますが、それを行う既存の手法は通常、各段階ごとに別個のモデル、カスタムの拡散プロセス、あるいは段階間の手の込んだ受け渡しを要求します。DFMは、Flow Matchingと呼ばれる標準的な技術を、多スケール画像表現の各レベル(本質的には、画像を詳細さが増していく層に分離するラプラシアンピラミッド)に独立して適用しつつ、全体を通じて単一の共有モデルを使用することで、これらの複雑さを回避します。学習時には、システムは各段階に対して異なるノイズレベルをサンプリングすることでプログレッシブ生成プロセスをシミュレートし、推論時には単純なスケジューラが粗いものから細かいものへと段階を順次進んでいきます。標準のImageNet-1Kベンチマークで512ピクセル解像度でテストしたところ、DFMは同じ学習計算量を使用して、FDDと呼ばれる主要な品質指標を、素のFlow Matchingと比べて35%、最良の競合する多段階手法と比べて26%削減しました。研究者らはまた、大規模な商用グレードの画像生成モデルであるFLUXのファインチューニングにもDFMを適用し、標準的なファインチューニングよりも速く目標の画像分布に収束し、FIDスコアを約29%削減することを発見しました。本研究の意義は主にその単純さにあります。すなわち、まったく新しいアーキテクチャや別個のモデルカスケードを必要とするのではなく、既存の学習パイプラインへの最小限の変更を通じて意味のある品質向上を実現します。
要旨
高次元の視覚モダリティを生成することは、計算負荷の高いタスクです。一般的な解決策は、出力を粗いものから細かいものへとスペクトル自己回帰的に合成するプログレッシブ生成です。拡散モデルはデノイジングの粗いものから細かいものへという性質から恩恵を受けますが、明示的な多段階アーキテクチャが採用されることはまれです。これらのアーキテクチャは、アプローチ全体の複雑さを増大させ、カスタムの拡散定式化、分解に依存した段階遷移、場当たり的なサンプラー、あるいはモデルカスケードの必要性をもたらしてきました。私たちの貢献であるDecomposable Flow Matching(DFM)は、視覚メディアのプログレッシブ生成のための、単純かつ効果的なフレームワークです。DFMは、ユーザーが定義した多スケール表現(ラプラシアンピラミッドなど)の各レベルで独立してFlow Matchingを適用します。私たちの実験が示すように、本アプローチは画像と動画の両方で視覚的品質を向上させ、従来の多段階フレームワークと比較して優れた結果を特徴とします。Imagenet-1k 512pxにおいて、DFMは同じ学習計算量のもとで、ベースアーキテクチャに対してFDDスコアで35.2%、最も性能の高いベースラインに対して26.4%の改善を達成します。FLUXのような大規模モデルのファインチューニングに適用すると、DFMは学習分布へのより速い収束速度を示します。重要なことに、これらの利点はすべて、単一のモデル、アーキテクチャの単純さ、そして既存の学習パイプラインへの最小限の変更で達成されます。
詳細
引用
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
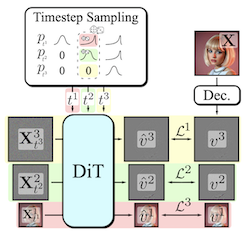
- Decomposable Flow Matchingとは何で、どのような問題に取り組んでいるのか。DFMは、多スケール表現のレベルにわたって独立してFlow Matchingを適用するプログレッシブ生成フレームワークであり、モデルカスケードやカスタムの拡散プロセスを必要とせずに、粗いものから細かいものへの画像・動画合成を改善します。
- DFMはどのようにしてサンプルをプログレッシブに生成するのか。視覚データをラプラシアンピラミッドのような段階に分解し、各段階に独自のフロータイムステップを割り当て、粗い構造から細かい詳細へと段階を進めるサンプラーを使用します。
- DFMはなぜ従来の多くのプログレッシブ生成手法よりも単純なのか。単一の共有モデルと標準的なFlow Matchingの定式化を維持し、段階ごとの別個のモデル、専用のサンプラー、複雑な遷移メカニズムを回避します。
- DFMは画像生成ベンチマークでどの程度の性能を発揮するのか。512pxおよび1024pxのImageNet-1Kにおいて、DFMは論文で報告された主要な指標とガイダンス設定にわたって、Flow Matching、カスケード型ベースライン、Pyramidal Flowを上回ります。
- DFMは大規模モデルのファインチューニングに役立つのか。はい、FLUXのファインチューニングに適用すると、DFMは同じ学習計算量のもとで標準的なファインチューニングよりも優れたFID、FDD、CLIP類似度に達し、目標分布へのより速い収束を示します。
主な貢献
- 本論文は、単一の共有生成器を維持しつつ視覚生成を分解可能な粗いものから細かいものへのプロセスに変える、Flow Matchingの単純な多スケール拡張を導入します。
- DFMはユーザー定義の分解をサポートしており、論文ではラプラシアンピラミッドを使用する一方、ウェーブレット、DCT、Fourier、あるいは多スケールオートエンコーダによる分解が自然な代替手段であることを指摘しています。
- 本手法には、学習タイムステップの分布、サンプリング閾値、段階ごとのサンプリングステップ、マスキング、分解の選択、計算量配分戦略の詳細な分析が含まれています。
- 実験は、ほとんどの設定で論文のプログレッシブ生成ベースラインの中で最良の報告値を含め、ImageNet-1K画像生成およびKinetics-700動画生成において強力な結果を示しています。
- FLUXのファインチューニング実験は、DFMが学習パイプラインへの最小限の変更で大規模な生成モデルの適応を改善できることを実証しています。
限界と注意点
- DFMは追加の学習およびサンプリングのハイパーパラメータを導入しますが、論文は、安定した設定が複数の実験にわたって転用できることを示す広範なアブレーション研究と実用的な指針を提供しています。
- 本フレームワークの性能は低周波構造と高周波詳細のバランスを取ることに依存するため、今後の研究は自動スケジューリングのポリシーを洗練できます。現在の結果は、このバランスが大きな品質向上を生み出せることをすでに示しています。
- 主な実装はラプラシアン分解を使用しており、DCT、ウェーブレット、多スケールオートエンコーダといった他の分解は、中核的な定式化の弱点ではなく有望な拡張として残されています。
- 大規模モデルの実験は、あらゆる展開設定で元のフロンティアモデルを改善すると主張するのではなく、FLUXを目標分布にファインチューニングすることに焦点を当てており、これにより結論が適切に範囲づけられつつ依然として実用的に価値あるものとなっています。
- DFMは、単独の推論専用アクセラレータというよりも、より優れたプログレッシブ生成のための学習時フレームワークと見なすのが最も適切であり、その単純さは、より速いサンプリングと展開に関する今後のシステム研究を補完するものとなります。
この結果の読み解き方
本論文は、プログレッシブな視覚生成への強力で洗練された貢献として読むのが最も適切です。DFMは、単一のFlow Matchingモデルで粗いものから細かいものへの合成の利点を捉え、ベンチマークにわたって画像と動画の品質を向上させ、大規模な生成システムのより優れたファインチューニングへの実用的な道筋を提供します。