Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Zusammenfassung der Pressemitteilung
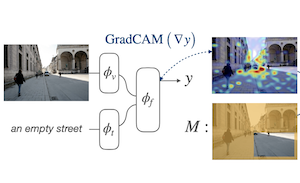
Forschende der Rice University und von Adobe Research haben eine neue Trainingstechnik entwickelt, die verbessert, wie KI-Vision-Language-Modelle Objekte und Regionen in Bildern lokalisieren, wenn ihnen eine Textbeschreibung gegeben wird. Das Problem, das sie angingen, besteht darin, dass große, auf Bild-Text-Paaren im Internetmaßstab trainierte Modelle Wörter zwar lose Bildregionen zuordnen können, ihnen aber nicht ausdrücklich beigebracht wird, Dinge präzise zu lokalisieren. Der Ansatz des Teams, genannt Attention Mask Consistency (AMC), funktioniert, indem er die gradientenbasierten "Erklärungs-Heatmaps" betrachtet, die ein Modell auf natürliche Weise erzeugt, wenn es entscheidet, ob ein Bild und ein Text zusammenpassen, und das Modell dann während des Trainings immer dann bestraft, wenn diese Heatmaps die falschen Teile des Bildes hervorheben – also Regionen außerhalb der von Menschen annotierten Bereiche. Die Bestrafung nimmt die Form eines Margin-Verlusts an, der das Modell dazu drängt, die Heatmap-Energie innerhalb der annotierten Regionen statt außerhalb zu konzentrieren. Entscheidend ist, dass die Methode keinen Objektdetektor als Zwischeninstanz benötigt, wie es bei den meisten konkurrierenden Ansätzen der Fall ist, und dass sie auf ein bestehendes Modell – in diesem Fall ALBEF – aufgesetzt werden kann, ohne von Grund auf neu zu trainieren. Auf dem Flickr30k-Benchmark für visuelles Grounding erreichte ein mit AMC trainiertes Modell eine Genauigkeit von 86,49 %, eine Verbesserung von mehr als fünf Prozentpunkten gegenüber dem besten zuvor veröffentlichten Ergebnis unter vergleichbarer Supervision, und es setzte zudem neue Bestmarken auf dem RefCOCO+-Datensatz für referenzierende Ausdrücke. Die Arbeit ist bedeutsam, weil sie einen vergleichsweise leichtgewichtigen Weg zu besserem räumlichem Schlussfolgern in Vision-Language-Modellen bietet, ohne die kostspielige Infrastruktur eines trainierten Objektdetektors zu erfordern.
Zusammenfassung
Wir schlagen einen margin-basierten Verlust für das Tuning kombinierter Vision-Language-Modelle vor, sodass deren gradientenbasierte Erklärungen mit den regionsbezogenen Annotationen übereinstimmen, die von Menschen für relativ kleinere Grounding-Datensätze bereitgestellt werden. Wir bezeichnen dieses Ziel als Attention Mask Consistency (AMC) und zeigen, dass es bessere Ergebnisse beim visuellen Grounding liefert als frühere Methoden, die darauf beruhen, Vision-Language-Modelle zur Bewertung der Ausgaben von Objektdetektoren einzusetzen. Insbesondere erzielt ein mit AMC zusätzlich zu den Standard-Vision-Language-Modellierungszielen trainiertes Modell eine Spitzengenauigkeit von 86,49 % auf dem Flickr30k-Benchmark für visuelles Grounding, eine absolute Verbesserung von 5,38 % im Vergleich zum besten bisherigen Modell, das unter demselben Supervisionsniveau trainiert wurde. Unser Ansatz schneidet auch auf etablierten Benchmarks für das Verständnis referenzierender Ausdrücke außerordentlich gut ab, wo er eine Genauigkeit von 80,34 % im einfachen Test von RefCOCO+ und von 64,55 % im schwierigen Split erreicht. AMC ist wirksam, einfach umzusetzen und allgemein anwendbar, da es von jedem Vision-Language-Modell übernommen werden kann und jede Art von regionsbezogenen Annotationen verwenden kann.
Details
Zitation
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}