Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Resumen de prensa
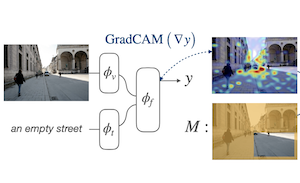
Investigadores de la Universidad Rice y Adobe Research han desarrollado una nueva técnica de entrenamiento que mejora la forma en que los modelos de visión y lenguaje de IA localizan objetos y regiones en imágenes cuando se les proporciona una descripción textual. El problema que abordaron es que, si bien los modelos grandes entrenados con pares de imagen y texto a escala de internet pueden emparejar de manera aproximada palabras con regiones de imágenes, no se les enseña explícitamente a localizar las cosas con precisión. El enfoque del equipo, llamado Attention Mask Consistency (AMC), funciona observando los "mapas de calor de explicación" basados en gradientes que un modelo produce de forma natural al decidir si una imagen y un texto coinciden, y luego penalizando al modelo durante el entrenamiento cada vez que esos mapas de calor resaltan las partes equivocadas de la imagen, es decir, regiones fuera de las áreas anotadas por humanos. La penalización toma la forma de una pérdida de margen que empuja al modelo a concentrar la energía del mapa de calor dentro de las regiones anotadas en lugar de fuera de ellas. De manera crucial, el método no requiere un detector de objetos como intermediario, que es como funcionan la mayoría de los enfoques competidores, y puede superponerse sobre un modelo existente —en este caso ALBEF— sin reentrenar desde cero. En el benchmark de grounding visual Flickr30k, un modelo entrenado con AMC alcanzó un 86.49% de precisión, una mejora de más de cinco puntos porcentuales sobre el mejor resultado publicado previamente bajo supervisión comparable, y también estableció nuevas marcas en el conjunto de datos de expresiones referenciales RefCOCO+. El trabajo es importante porque ofrece un camino relativamente ligero hacia un mejor razonamiento espacial en los modelos de visión y lenguaje sin requerir la costosa infraestructura de un detector de objetos entrenado.
resumen
Proponemos una pérdida basada en márgenes para ajustar modelos conjuntos de visión y lenguaje de modo que sus explicaciones basadas en gradientes sean consistentes con las anotaciones a nivel de región proporcionadas por humanos para conjuntos de datos de grounding relativamente más pequeños. Nos referimos a este objetivo como Attention Mask Consistency (AMC) y demostramos que produce resultados de grounding visual superiores a los de métodos previos que dependen de usar modelos de visión y lenguaje para puntuar las salidas de detectores de objetos. En particular, un modelo entrenado con AMC sobre objetivos estándar de modelado de visión y lenguaje obtiene una precisión de estado del arte del 86.49% en el benchmark de grounding visual Flickr30k, una mejora absoluta del 5.38% en comparación con el mejor modelo previo entrenado bajo el mismo nivel de supervisión. Nuestro enfoque también se desempeña excepcionalmente bien en benchmarks consolidados de comprensión de expresiones referenciales, donde obtiene un 80.34% de precisión en la prueba fácil de RefCOCO+ y un 64.55% en la división difícil. AMC es efectivo, fácil de implementar y general, ya que puede ser adoptado por cualquier modelo de visión y lenguaje y puede usar cualquier tipo de anotaciones de región.
detalles
cita
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}