Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu từ Rice University và Adobe Research đã phát triển một kỹ thuật huấn luyện mới cải thiện cách các mô hình AI thị giác-ngôn ngữ xác định chính xác các đối tượng và vùng trong ảnh khi được cung cấp một mô tả văn bản. Vấn đề mà họ giải quyết là trong khi các mô hình lớn được huấn luyện trên các cặp ảnh-văn bản quy mô internet có thể khớp một cách lỏng lẻo các từ với các vùng ảnh, chúng không được dạy một cách tường minh để định vị mọi thứ một cách chính xác. Cách tiếp cận của nhóm, gọi là Attention Mask Consistency (AMC), hoạt động bằng cách nhìn vào các "bản đồ nhiệt giải thích" dựa trên gradient mà một mô hình tự nhiên tạo ra khi quyết định liệu một ảnh và văn bản có khớp hay không, và sau đó phạt mô hình trong quá trình huấn luyện mỗi khi các bản đồ nhiệt đó làm nổi bật các phần sai của ảnh — tức là các vùng nằm ngoài các khu vực được con người chú thích. Hình phạt mang hình thức của một hàm mất mát lề đẩy mô hình tập trung năng lượng của bản đồ nhiệt vào bên trong các vùng được chú thích thay vì bên ngoài chúng. Quan trọng là, phương pháp không đòi hỏi một bộ phát hiện đối tượng làm trung gian, đó là cách hầu hết các cách tiếp cận cạnh tranh hoạt động, và nó có thể được xếp chồng lên trên một mô hình hiện có — trong trường hợp này là ALBEF — mà không cần huấn luyện lại từ đầu. Trên benchmark định vị thị giác Flickr30k, một mô hình được huấn luyện với AMC đạt độ chính xác 86.49%, một sự cải thiện hơn năm điểm phần trăm so với kết quả đã công bố tốt nhất trước đây dưới sự giám sát tương đương, và nó cũng thiết lập các kỷ lục mới trên bộ dữ liệu biểu thức tham chiếu RefCOCO+. Công trình có ý nghĩa vì nó mang lại một con đường tương đối nhẹ để có khả năng suy luận không gian tốt hơn trong các mô hình thị giác-ngôn ngữ mà không đòi hỏi hạ tầng tốn kém của một bộ phát hiện đối tượng đã được huấn luyện.
tóm tắt
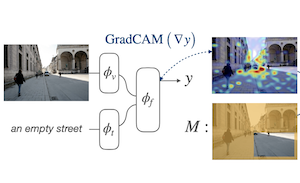
Chúng tôi đề xuất một hàm mất mát dựa trên lề (margin) để điều chỉnh các mô hình thị giác-ngôn ngữ kết hợp sao cho các lời giải thích dựa trên gradient của chúng nhất quán với các chú thích ở cấp độ vùng do con người cung cấp cho các bộ dữ liệu định vị tương đối nhỏ hơn. Chúng tôi gọi mục tiêu này là Attention Mask Consistency (AMC) và chứng minh rằng nó tạo ra các kết quả định vị thị giác vượt trội so với các phương pháp trước đây vốn dựa vào việc sử dụng các mô hình thị giác-ngôn ngữ để chấm điểm các đầu ra của các bộ phát hiện đối tượng. Đặc biệt, một mô hình được huấn luyện với AMC trên nền các mục tiêu mô hình hóa thị giác-ngôn ngữ tiêu chuẩn đạt được độ chính xác tốt nhất hiện nay là 86.49% trên benchmark định vị thị giác Flickr30k, một sự cải thiện tuyệt đối 5.38% so với mô hình tốt nhất trước đây được huấn luyện dưới cùng một mức giám sát. Cách tiếp cận của chúng tôi cũng hoạt động cực kỳ tốt trên các benchmark đã được thiết lập cho việc hiểu biểu thức tham chiếu, nơi nó đạt được độ chính xác 80.34% trong bài kiểm tra dễ của RefCOCO+, và 64.55% trong phần phân chia khó. AMC hiệu quả, dễ triển khai, và tổng quát vì nó có thể được áp dụng bởi bất kỳ mô hình thị giác-ngôn ngữ nào, và có thể sử dụng bất kỳ loại chú thích vùng nào.
chi tiết
trích dẫn
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}