Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Résumé du communiqué de presse
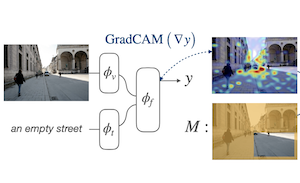
Des chercheurs de Rice University et d'Adobe Research ont mis au point une nouvelle technique d'entraînement qui améliore la façon dont les modèles vision-langage d'IA localisent les objets et les régions dans les images à partir d'une description textuelle. Le problème qu'ils ont abordé est que, si les grands modèles entraînés sur des paires image-texte à l'échelle d'Internet peuvent grossièrement faire correspondre des mots à des régions d'image, on ne leur apprend pas explicitement à localiser les choses avec précision. L'approche de l'équipe, appelée Attention Mask Consistency (AMC), consiste à examiner les « cartes de chaleur explicatives » fondées sur le gradient qu'un modèle produit naturellement lorsqu'il décide si une image et un texte correspondent, puis à pénaliser le modèle durant l'entraînement chaque fois que ces cartes de chaleur mettent en évidence les mauvaises parties de l'image — c'est-à-dire des régions situées en dehors des zones annotées par des humains. La pénalité prend la forme d'une perte à marge qui pousse le modèle à concentrer l'énergie de la carte de chaleur à l'intérieur des régions annotées plutôt qu'à l'extérieur. De manière cruciale, la méthode ne nécessite pas de détecteur d'objets comme intermédiaire, contrairement à la plupart des approches concurrentes, et elle peut être superposée à un modèle existant — en l'occurrence ALBEF — sans réentraînement à partir de zéro. Sur le banc d'essai d'ancrage visuel Flickr30k, un modèle entraîné avec AMC a atteint une précision de 86,49%, soit une amélioration de plus de cinq points de pourcentage par rapport au meilleur résultat précédemment publié à supervision comparable, et il a également établi de nouvelles références sur le jeu de données d'expressions de référence RefCOCO+. Ce travail est important car il offre une voie relativement légère vers un meilleur raisonnement spatial dans les modèles vision-langage sans nécessiter l'infrastructure coûteuse d'un détecteur d'objets entraîné.
résumé
Nous proposons une fonction de perte fondée sur une marge pour ajuster des modèles vision-langage conjoints afin que leurs explications fondées sur le gradient soient cohérentes avec des annotations au niveau des régions fournies par des humains pour des jeux de données d'ancrage relativement plus petits. Nous désignons cet objectif par Attention Mask Consistency (AMC) et démontrons qu'il produit de meilleurs résultats d'ancrage visuel que les méthodes antérieures qui s'appuient sur des modèles vision-langage pour noter les sorties de détecteurs d'objets. En particulier, un modèle entraîné avec AMC par-dessus des objectifs standard de modélisation vision-langage obtient une précision de pointe de 86,49% sur le banc d'essai d'ancrage visuel Flickr30k, soit une amélioration absolue de 5,38% par rapport au meilleur modèle antérieur entraîné au même niveau de supervision. Notre approche obtient également d'excellents résultats sur des bancs d'essai établis de compréhension d'expressions de référence, où elle atteint une précision de 80,34% sur le test facile de RefCOCO+ et de 64,55% sur la partition difficile. AMC est efficace, facile à mettre en œuvre et général, car il peut être adopté par tout modèle vision-langage et utiliser tout type d'annotations de régions.
détails
citation
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}