プレスリリース要約
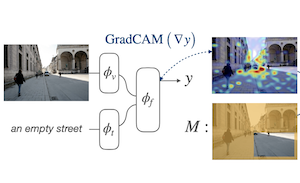
ライス大学とAdobe Researchの研究者らは、テキストによる説明を与えられたときに、AIの視覚言語モデルが画像内の物体や領域を特定する仕方を改善する新しい訓練技術を開発しました。彼らが取り組んだ問題は、インターネット規模の画像テキストペアで訓練された大規模モデルが語を画像領域に大まかに対応づけることはできても、物事を正確に位置特定するよう明示的には教えられていないことです。研究チームのアプローチは、Attention Mask Consistency(AMC、アテンションマスク整合性)と呼ばれ、画像とテキストが一致するかどうかを判断する際にモデルが自然に生成する勾配ベースの「説明ヒートマップ」を見て、それらのヒートマップが画像の誤った部分、すなわち人間がアノテーションした領域の外側を強調するたびに、訓練中にモデルにペナルティを与えることで機能します。このペナルティは、ヒートマップのエネルギーをアノテーション領域の外側ではなく内側に集中させるようモデルを促すマージン損失の形をとります。決定的に重要なのは、この手法が、ほとんどの競合アプローチが行うような仲介役としての物体検出器を必要とせず、既存のモデル、この場合はALBEFの上に、ゼロから再訓練することなく重ねられることです。Flickr30k視覚的グラウンディングベンチマークでは、AMCを用いて訓練されたモデルが86.49%の精度に達し、これは同等の教師のもとでこれまでに公表された最良の結果を5パーセントポイント以上上回る改善であり、RefCOCO+参照表現データセットでも新たな記録を打ち立てました。この研究が重要なのは、訓練された物体検出器という高価なインフラを必要とせずに、視覚言語モデルにおけるより優れた空間推論への比較的軽量な道筋を提供するからです。
要旨
私たちは、結合型の視覚言語モデルを調整して、その勾配ベースの説明が、比較的小規模なグラウンディングデータセットに対して人間が提供する領域レベルのアノテーションと整合するようにするための、マージンベースの損失を提案します。私たちはこの目的をAttention Mask Consistency(AMC、アテンションマスク整合性)と呼び、それが、物体検出器の出力をスコアリングするために視覚言語モデルを用いることに依存する従来の手法よりも優れた視覚的グラウンディング結果を生み出すことを実証します。特に、標準的な視覚言語モデリングの目的の上にAMCを用いて訓練されたモデルは、Flickr30k視覚的グラウンディングベンチマークで86.49%という最先端の精度を獲得し、これは同じレベルの教師のもとで訓練された従来の最良モデルと比較して絶対値で5.38%の改善です。私たちのアプローチは、参照表現理解の確立されたベンチマークでも非常に優れた性能を発揮し、RefCOCO+の易しいテストで80.34%、難しい分割で64.55%の精度を獲得します。AMCは効果的で実装が容易であり、どんな視覚言語モデルにも採用でき、どんな種類の領域アノテーションも使用できるため汎用的です。
詳細
引用
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}