보도 자료 요약
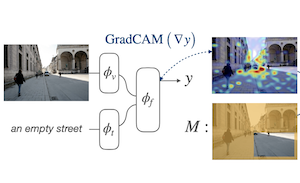
라이스 대학교와 Adobe Research의 연구진은 텍스트 설명이 주어졌을 때 AI 비전-언어 모델이 이미지 속 객체와 영역을 정확히 짚어내는 방식을 개선하는 새로운 학습 기법을 개발했다. 그들이 다룬 문제는 인터넷 규모의 이미지-텍스트 쌍으로 학습된 대규모 모델이 단어를 이미지 영역에 느슨하게 매칭할 수 있지만 정밀하게 위치를 찾도록 명시적으로 학습되지는 않는다는 점이다. Attention Mask Consistency (AMC)라고 불리는 이 팀의 접근법은 모델이 이미지와 텍스트가 일치하는지 결정할 때 자연스럽게 생성하는 그래디언트 기반 "설명 히트맵"을 살펴본 다음, 그 히트맵이 이미지의 잘못된 부분 — 즉, 인간이 주석을 단 영역 밖의 영역 — 을 강조할 때마다 학습 중에 모델에 페널티를 부과함으로써 작동한다. 이 페널티는 모델이 히트맵 에너지를 주석 영역 밖이 아니라 안에 집중하도록 밀어붙이는 마진 손실의 형태를 띤다. 결정적으로, 이 방법은 대부분의 경쟁 접근법이 작동하는 방식인 중간 매개체로서의 객체 검출기를 요구하지 않으며, 기존 모델 — 이 경우 ALBEF — 위에 처음부터 재학습할 필요 없이 얹을 수 있다. Flickr30k 시각적 고정 벤치마크에서 AMC로 학습된 모델은 86.49%의 정확도에 도달했는데, 이는 비슷한 감독 하의 이전 최고 발표 결과보다 5%포인트 이상 향상된 것이며, RefCOCO+ 참조 표현 데이터셋에서도 새로운 기록을 세웠다. 이 연구가 중요한 이유는 학습된 객체 검출기의 비싼 인프라를 요구하지 않으면서 비전-언어 모델의 더 나은 공간 추론으로 가는 비교적 가벼운 길을 제공하기 때문이다.
초록
우리는 비교적 작은 고정(grounding) 데이터셋에 대해 인간이 제공한 영역 수준 주석과 그래디언트 기반 설명이 일관되도록 결합 비전-언어 모델을 조정하기 위한 마진 기반 손실(margin-based loss)을 제안한다. 우리는 이 목표를 Attention Mask Consistency (AMC)라고 부르며, 이것이 객체 검출기의 출력을 점수화하기 위해 비전-언어 모델을 사용하는 데 의존하는 이전 방법들보다 우수한 시각적 고정 결과를 산출함을 입증한다. 특히, 표준 비전-언어 모델링 목표 위에 AMC로 학습된 모델은 Flickr30k 시각적 고정 벤치마크에서 86.49%라는 최첨단 정확도를 달성하는데, 이는 동일한 수준의 감독 하에서 학습된 이전 최고 모델 대비 5.38%의 절대적 향상이다. 우리 접근법은 또한 참조 표현 이해(referring expression comprehension)를 위한 확립된 벤치마크에서도 매우 우수한 성능을 보여, RefCOCO+의 easy 테스트에서 80.34% 정확도를, 어려운 분할에서 64.55%를 달성한다. AMC는 효과적이고 구현이 쉬우며, 어떤 비전-언어 모델에도 채택될 수 있고 어떤 유형의 영역 주석도 사용할 수 있다는 점에서 범용적이다.
세부 정보
인용
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}