Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Краткое изложение пресс-релиза
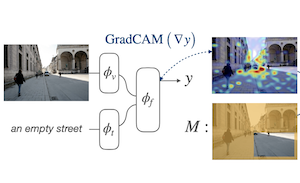
Исследователи из Rice University и Adobe Research разработали новую технику обучения, которая улучшает то, как модели зрения и языка определяют местоположение объектов и регионов на изображениях при наличии текстового описания. Проблема, которую они решали, состоит в том, что хотя большие модели, обученные на парах изображение-текст интернет-масштаба, могут приблизительно сопоставлять слова с регионами изображения, их явно не учат точно локализовать объекты. Подход команды под названием Attention Mask Consistency (AMC) работает, рассматривая градиентные "объяснительные тепловые карты", которые модель естественным образом создаёт, решая, совпадают ли изображение и текст, а затем штрафуя модель во время обучения всякий раз, когда эти тепловые карты выделяют неправильные части изображения — то есть регионы за пределами размеченных людьми областей. Штраф принимает форму потери с отступом (margin), которая побуждает модель концентрировать энергию тепловой карты внутри размеченных регионов, а не за их пределами. Что особенно важно, метод не требует детектора объектов в качестве посредника, как работает большинство конкурирующих подходов, и может быть надстроен поверх существующей модели — в данном случае ALBEF — без переобучения с нуля. На бенчмарке визуальной локализации Flickr30k модель, обученная с AMC, достигла точности 86.49%, что является улучшением более чем на пять процентных пунктов по сравнению с лучшим ранее опубликованным результатом при сопоставимом надзоре, и она также установила новые рекорды на наборе данных referring expression RefCOCO+. Работа важна, потому что предлагает сравнительно лёгкий путь к лучшему пространственному рассуждению в моделях зрения и языка без необходимости в дорогостоящей инфраструктуре обученного детектора объектов.
аннотация
Мы предлагаем функцию потерь на основе отступа (margin) для настройки совместных моделей зрения и языка таким образом, чтобы их объяснения на основе градиентов согласовывались с аннотациями на уровне регионов, предоставленными людьми, для сравнительно небольших наборов данных локализации. Мы называем эту целевую функцию Attention Mask Consistency (AMC) и демонстрируем, что она даёт превосходящие результаты визуальной локализации по сравнению с предыдущими методами, которые опираются на использование моделей зрения и языка для оценки выходов детекторов объектов. В частности, модель, обученная с AMC поверх стандартных целевых функций моделирования зрения и языка, достигает точности на современном уровне 86.49% на бенчмарке визуальной локализации Flickr30k, что является абсолютным улучшением на 5.38% по сравнению с лучшей предыдущей моделью, обученной при том же уровне надзора. Наш подход также исключительно хорошо работает на устоявшихся бенчмарках понимания referring expression, где он достигает точности 80.34% на лёгком тесте RefCOCO+ и 64.55% на сложном разбиении. AMC эффективен, прост в реализации и универсален, поскольку может быть применён любой моделью зрения и языка и может использовать любой тип аннотаций регионов.
подробности
цитирование
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}