Where and Who? Automatic Semantic-Aware Person Composition
Resumen de prensa
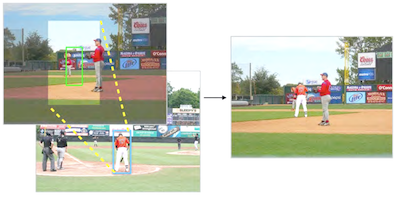
Investigadores de la Universidad de Virginia han construido un sistema que puede insertar automáticamente una figura humana de apariencia realista en una fotografía sin ninguna orientación humana sobre dónde colocarla o a quién usar. La mayoría de las herramientas de composición de fotos existentes manejan el trabajo técnico de fusionar los bordes y emparejar los colores, pero aún dejan al usuario la tarea de elegir un sujeto de primer plano, decidir dónde colocarlo y determinar qué tan grande debe ser. El nuevo sistema aborda computacionalmente esas decisiones de criterio entrenando una red neuronal convolucional ramificada con decenas de miles de imágenes anotadas del conjunto de datos MS-COCO, enseñándole a predecir ubicaciones y tamaños plausibles para una persona dada únicamente la escena de fondo. Una vez que se predice un cuadro delimitador, el sistema busca en un conjunto de aproximadamente 4.100 recortes de personas segmentados manualmente, usando características profundas de un modelo ResNet50 preentrenado para emparejar tanto el tipo general de escena como el entorno local inmediato antes de fusionar la figura elegida mediante alpha matting. En un estudio de usuarios colaborativo en Amazon Mechanical Turk, los jueces humanos calificaron las composiciones del sistema como reales alrededor del 44 por ciento de las veces, en comparación con aproximadamente el 18 al 28 por ciento de tres enfoques de referencia, aunque las fotografías reales aún obtuvieron una puntuación cercana al 90 por ciento. La diferencia se reduce considerablemente cuando se eliminan la textura y la iluminación, lo que sugiere que los desajustes de color e iluminación —no la colocación ni la selección de la figura— son el principal obstáculo restante. Los investigadores afirman que el trabajo representa un primer paso hacia herramientas que podrían asistir a diseñadores gráficos, cineastas y artistas de storyboard que actualmente dedican un tiempo considerable a ensamblar manualmente tales escenas.
resumen
La composición de imágenes es un método utilizado para generar imágenes realistas pero falsas insertando contenido de una imagen en otra. El trabajo previo en composición se ha centrado en mejorar la compatibilidad de apariencia entre un segmento de primer plano seleccionado por el usuario y una imagen de fondo (es decir, la consistencia de color e iluminación). En este trabajo, en cambio, desarrollamos un modelo de composición totalmente automatizado que además aprende a seleccionar y transformar segmentos de primer plano compatibles a partir de una gran colección, dado únicamente un fondo de imagen de entrada. Para simplificar la tarea, restringimos nuestro problema centrándonos en la composición de instancias humanas, porque los segmentos humanos exhiben fuertes correlaciones con su fondo y por la disponibilidad de grandes cantidades de datos anotados. Desarrollamos una novedosa red neuronal convolucional (CNN) ramificada que predice conjuntamente ubicaciones candidatas de personas dada una imagen de fondo. Luego utilizamos representaciones de características profundas preentrenadas para recuperar instancias de personas de una gran base de datos de segmentos. Los resultados experimentales muestran que nuestro modelo puede generar imágenes compuestas que parecen visualmente convincentes. También desarrollamos una interfaz de usuario para demostrar la aplicación potencial de nuestro método.
detalles
cita
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}