SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Resumen de prensa
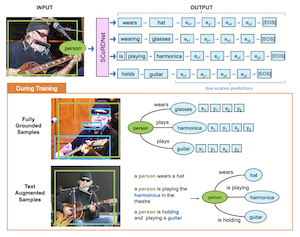
Investigadores de la Universidad Rice y Adobe Research han desarrollado un sistema llamado SCoRD — abreviatura de Subject-Conditional Relation Detection (Detección de Relaciones Condicionada al Sujeto) — que, dado un objeto específico en una foto, identifica automáticamente todo con lo que ese objeto está interactuando, cuáles son esas interacciones, y dónde se ubican los otros objetos en la imagen. En lugar de intentar mapear todas las relaciones posibles entre todos los objetos de una escena, lo que rápidamente se vuelve poco práctico, el sistema se centra en un único sujeto elegido y cataloga exhaustivamente solo sus conexiones relevantes. El equipo construyó su modelo, SCoRDNet, como un decodificador de secuencia autorregresivo que produce pares relación-objeto junto con coordenadas de cuadros delimitadores como un flujo de tokens, y diseñaron un benchmark basado en el conjunto de datos Open Images específicamente elaborado para que los datos de entrenamiento y prueba tengan estadísticas de relación no coincidentes — lo que hace más difícil que un modelo simplemente memorice patrones comunes. Un hallazgo clave es que el rendimiento del sistema en tipos de relación raros o nunca antes vistos mejoró sustancialmente cuando el entrenamiento se complementó con tripletes de relación ruidosos extraídos automáticamente de descripciones de imágenes, incluso cuando esas descripciones no venían con ninguna anotación de cuadro delimitador. En relaciones que el modelo base nunca había encontrado durante el entrenamiento, la versión aumentada con texto logró un recall del 33.8% para los pares relación-objeto y del 26.75% para sus ubicaciones de caja, en comparación con casi cero para el modelo de referencia sin asistencia. El trabajo es importante porque ofrece un camino más escalable hacia la detección de relaciones de vocabulario abierto: en lugar de requerir conjuntos de datos costosos y completamente anotados para cada interacción posible, el enfoque sugiere que las grandes colecciones de imágenes con descripciones ya disponibles en internet podrían expandir drásticamente lo que tales sistemas pueden reconocer y localizar.
resumen
Proponemos la Detección de Relaciones Condicionada al Sujeto (Subject-Conditional Relation Detection, SCoRD), donde, condicionada a un sujeto de entrada, el objetivo es predecir todas sus relaciones con otros objetos en una escena junto con sus ubicaciones. Basándonos en el conjunto de datos Open Images, proponemos un desafiante benchmark OIv6-SCoRD de tal manera que las particiones de entrenamiento y prueba presentan un cambio de distribución en términos de las estadísticas de ocurrencia de los tripletes $\langle$sujeto, relación, objeto$\rangle$. Para resolver este problema, proponemos un modelo autorregresivo que, dado un sujeto, predice sus relaciones, objetos y ubicaciones de objetos al expresar esta salida como una secuencia de tokens. Primero, mostramos que los métodos previos de predicción de grafos de escena no logran producir una enumeración tan exhaustiva de pares relación-objeto cuando se condicionan a un sujeto en este benchmark. En particular, obtenemos un recall@3 del 83.8% para nuestras predicciones de relación-objeto en comparación con el 49.75% obtenido por un detector reciente de grafos de escena. Luego, mostramos una generalización mejorada tanto en las predicciones de relación-objeto como de caja de objeto al aprovechar durante el entrenamiento pares relación-objeto obtenidos automáticamente de descripciones textuales y para los cuales no hay anotaciones de caja de objeto disponibles. En particular, para los tripletes $\langle$sujeto, relación, objeto$\rangle$ para los cuales no hay ubicaciones de objetos disponibles durante el entrenamiento, podemos obtener un recall@3 del 33.80% para los pares relación-objeto y del 26.75% para sus ubicaciones de caja.
detalles
cita
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es SCoRD? SCoRD es una tarea de detección de relaciones condicionada al sujeto en la que un modelo recibe un sujeto elegido en una imagen y predice las relaciones de ese sujeto, los objetos relacionados y las ubicaciones de los objetos.
- ¿En qué se diferencia SCoRD de la generación completa de grafos de escena? En lugar de predecir cada relación entre cada objeto, SCoRD se centra en describir exhaustivamente las relaciones de un sujeto consultado, lo que a menudo es más práctico para aplicaciones posteriores.
- ¿Qué es SCoRDNet? SCoRDNet es un modelo de visión y lenguaje autorregresivo que representa las predicciones de relación-objeto y las coordenadas de los cuadros delimitadores como una secuencia de tokens.
- ¿Por qué usar datos aumentados con texto? Los tripletes relación-objeto derivados de descripciones proporcionan una supervisión escalable para relaciones raras o nunca vistas, incluso cuando las descripciones no incluyen anotaciones de caja de objeto.
- ¿Qué evalúa el benchmark OIv6-SCoRD? El benchmark crea cambios de distribución entre entrenamiento y prueba en los tripletes sujeto-relación-objeto, lo que lo convierte en una prueba sólida de generalización más allá de las estadísticas de relación memorizadas.
Contribuciones principales
- El artículo define la Detección de Relaciones Condicionada al Sujeto como una alternativa enfocada a la generación completa de grafos de escena para describir las relaciones de un objeto especificado.
- Introduce OIv6-SCoRD, un benchmark diseñado para someter a prueba la detección de relaciones bajo cambios de distribución en las estadísticas de relación-objeto.
- SCoRDNet plantea la predicción de relación, objeto y localización como un problema unificado de decodificación de tokens, lo que permite manejar la supervisión anclada y no anclada en un solo modelo.
- El artículo muestra que el entrenamiento aumentado con texto a partir de descripciones mejora sustancialmente la generalización a pares relación-objeto subrepresentados y nunca vistos.
- SCoRDNet supera las adaptaciones condicionadas al sujeto de los métodos de grafos de escena en la predicción de relación-objeto y demuestra que las descripciones no ancladas pueden mejorar tanto la predicción de relaciones como la localización de objetos.
Limitaciones y advertencias
- SCoRD asume que un sujeto y su caja se proporcionan como entrada, lo que mantiene la tarea enfocada y la hace muy adecuada para aplicaciones donde un usuario o un detector previo identifica el objeto de interés.
- Los tripletes de relación derivados de descripciones son ruidosos y a menudo carecen de cajas de objeto, pero el artículo convierte esta señal débil en una fortaleza al mostrar que aún mejora la generalización cuando se combina con datos anclados.
- El método se evalúa en un benchmark derivado de Open Images y fuentes de descripciones como COCO y Conceptual Captions, dejando colecciones de imágenes de mundo abierto más amplias como pruebas naturales siguientes.
- SCoRDNet predice cajas mediante decodificación de secuencia en lugar de un refinamiento de caja especializado, lo que deja espacio para futuras combinaciones con módulos de localización más potentes.
- La tarea se centra en relaciones centradas en el sujeto en lugar de grafos de escena completos, lo que ofrece una formulación práctica y escalable a la vez que complementa los sistemas más amplios de generación de grafos.
Cómo interpretar este resultado
Este artículo se lee mejor como un sólido paso hacia la comprensión escalable de relaciones visuales: SCoRD reformula la detección de relaciones en torno a un sujeto consultado, y SCoRDNet muestra que la supervisión económica basada en descripciones puede expandir significativamente qué pares relación-objeto puede reconocer y localizar un modelo.