ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Résumé du communiqué de presse
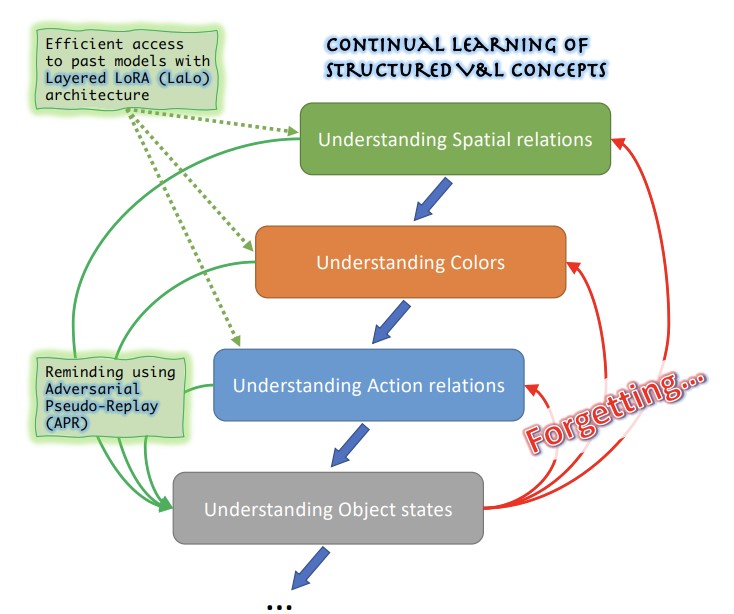
Des chercheurs du MIT-IBM Watson AI Lab, de Georgia Tech, de l'Université Rice, d'IBM Research et de Stanford se sont attaqués à un problème concret mais peu exploré des grands modèles d'IA vision-et-langage : ces systèmes ont tendance à peiner à comprendre les concepts relationnels et descriptifs nuancés — comme les couleurs, les tailles, les positions spatiales et les états des objets — et lorsque les ingénieurs tentent de corriger une telle faiblesse en affinant le modèle sur de nouvelles données, le modèle tend à oublier comment gérer les faiblesses précédemment corrigées, un phénomène connu sous le nom d'oubli catastrophique. La situation est rendue plus difficile par le fait que les données utilisées pour identifier et corriger chaque problème sont souvent privées et ne peuvent être conservées ni réutilisées d'une session d'entraînement à l'autre. Pour remédier à cela, l'équipe a créé ConStruct-VL, le premier benchmark spécifiquement conçu pour évaluer l'apprentissage continu de ces concepts visuels-langagiers structurés sans accès aux données des tâches précédentes et sans aucune indication, au moment du test, sur le type de concept évalué. Ils ont également développé deux contributions techniques complémentaires : une architecture Layered-LoRA (LaLo) qui empile des modules adaptateurs légers et de faible rang par-dessus un modèle de base figé pour chaque nouvelle tâche, permettant au système d'accéder efficacement au modèle de n'importe quelle tâche antérieure pendant l'entraînement sans recharger les poids ; et une méthode de Pseudo-Rejeu Adversarial (APR) qui utilise ces modèles passés pour générer des exemples d'entraînement négatifs délicats — par exemple, en modifiant subtilement une description textuelle pour y inclure un mot de couleur incompatible avec l'image associée — ensuite utilisés pour rappeler au modèle actuel ce qu'il avait appris précédemment. Testée sur le modèle vision-langage BLIP à travers plusieurs séquences de tâches issues des jeux de données Visual Genome et Visual Attributes in the Wild, l'approche combinée a réduit l'oubli moyen d'environ cinq fois et amélioré la précision finale de jusqu'à 6,8 points de pourcentage par rapport aux meilleures méthodes concurrentes d'apprentissage continu sans données, tout en n'utilisant qu'environ 2,8 % des paramètres du modèle complet — des résultats qui comptent car ils suggèrent une voie viable pour corriger en continu les modèles d'IA dans des déploiements réels sensibles à la confidentialité, sans dégrader les améliorations antérieures.
résumé
Récemment, les modèles de fondation Vision-et-Langage (VL) pré-entraînés à grande échelle ont démontré des capacités remarquables dans de nombreuses tâches en aval en zero-shot, obtenant des résultats compétitifs pour la reconnaissance d'objets définis par de simples invites textuelles courtes. Cependant, il a également été montré que les modèles VL restent fragiles dans le raisonnement sur les Concepts VL Structurés (SVLC), comme la capacité à reconnaître les attributs, les états des objets et les relations entre objets. Cela conduit à des erreurs de raisonnement, qui doivent être corrigées au fur et à mesure qu'elles surviennent en enseignant aux modèles VL les compétences SVLC manquantes ; souvent, cela doit être réalisé à l'aide de données privées là où le problème a été détecté, ce qui mène naturellement à un cadre d'apprentissage VL continu sans données (sans identifiant de tâche). Dans ce travail, nous présentons le premier benchmark d'Apprentissage Continu de Concepts VL Structurés sans Données (ConStruct-VL) et montrons qu'il est difficile pour de nombreuses stratégies d'apprentissage continu sans données existantes. Nous proposons donc une méthode sans données reposant sur une nouvelle approche de Pseudo-Rejeu Adversarial (APR) qui génère des rappels adversariaux des tâches passées à partir des modèles de tâches passées. Pour utiliser cette méthode de manière efficace, nous proposons également une architecture neuronale continue à paramètres efficients, Layered-LoRA (LaLo), permettant un accès sans coût mémoire à tous les modèles passés au moment de l'entraînement. Nous montrons que cette approche surpasse toutes les méthodes sans données de jusqu'à ~7 % tout en égalant même certains niveaux de rejeu d'expérience (prohibitif pour les applications où la confidentialité des données doit être préservée). Notre code est disponible publiquement à l'adresse https://github.com/jamessealesmith/ConStruct-VL
détails
citation
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}